
PDF ถูกใช้กันอย่างแพร่หลายในการจัดเก็บและแบ่งปันเอกสารประเภทต่างๆ รวมถึงรายงาน งานนำเสนอ และโบรชัวร์ อย่างไรก็ตาม เมื่อต้องแยกภาพออกจากไฟล์เหล่านี้ กระบวนการนี้อาจใช้เวลานานและยุ่งยาก ไม่ว่าคุณจะต้องแยกภาพเพื่อแก้ไข วิเคราะห์ หรือรวมไว้ในโปรเจ็กต์ของคุณเอง การมีวิธีการที่เชื่อถือได้และมีประสิทธิภาพจึงมีความสำคัญ ดังนั้น การใช้ประโยชน์จากความสามารถของ SDK การเขียนโปรแกรมจะช่วยลดขั้นตอนการแยกภาพ ประหยัดเวลาและความพยายามอันมีค่า ในบทความนี้ เราจะมาเจาะลึกรายละเอียดเกี่ยวกับวิธีการแยกภาพออกจากไฟล์ PDF โดยใช้ Python Cloud SDK และปลดล็อกระดับใหม่แห่งประสิทธิภาพและความสะดวก
SDK การประมวลผล PDF บนคลาวด์
เมื่อพูดถึงการแยกภาพจากไฟล์ PDF โดยใช้ Python Aspose.PDF Cloud API เป็นเครื่องมือที่มีประสิทธิภาพและอเนกประสงค์ ด้วย Aspose.PDF Cloud SDK สำหรับ Python คุณไม่เพียงแต่สามารถแยกภาพจาก PDF เท่านั้น แต่ยังทำงานอื่นๆ อีกมากมาย เช่น แปลง PDF เป็นรูปแบบต่างๆ เพิ่มคำอธิบายประกอบ รวมหรือแยกเอกสาร PDF และอื่นๆ อีกมากมาย นอกจากนี้ SDK ยังมีชุด API ที่ครอบคลุมซึ่งช่วยให้คุณจัดการไฟล์ PDF ได้ด้วยโปรแกรม ช่วยประหยัดเวลาและความพยายามของคุณ
ตอนนี้เพื่อติดตั้ง SDK โปรดดาวน์โหลดจากที่เก็บ PIP หรือ GitHub จากนั้นให้รันคำสั่งต่อไปนี้บนเทอร์มินัล/พรอมต์คำสั่งเพื่อติดตั้ง SDK เวอร์ชันล่าสุดบนระบบ
pip install asposepdfcloud
PyCharm IDE
หากคุณใช้ PyCharm IDE คุณสามารถเพิ่ม SDK เป็นส่วนที่ต้องมีในโปรเจ็กต์ของคุณได้โดยตรง
ไฟล์ ->การตั้งค่า ->โปรเจ็กต์ ->Python Interpreter ->asposepdfcloud
รูปภาพ 1:- ตัวเลือกการตั้งค่า PyCharm
รูปภาพ 2:- แพ็กเกจ Aspose.PDF Cloud Python
ขั้นตอนสำคัญอีกประการหนึ่งคือการสร้างบัญชีฟรีบน cloud Dashboard โดยใช้บัญชี GitHub หรือ Google หรือคลิกปุ่ม สร้างบัญชีใหม่ แล้วระบุข้อมูลที่จำเป็น และรับข้อมูลประจำตัวลูกค้าส่วนบุคคลของคุณ
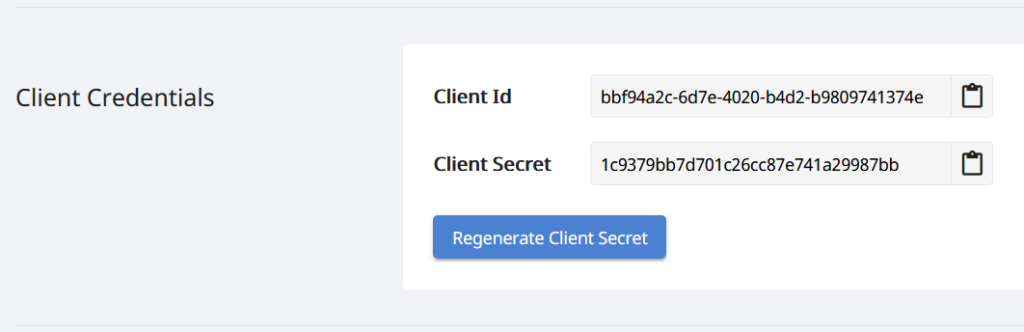
รูปภาพ 3:- ข้อมูลประจำตัวของลูกค้าบนแดชบอร์ดระบบคลาวด์
ดึงภาพจาก PDF ใน Python
โปรดปฏิบัติตามขั้นตอนด้านล่างเพื่อแยกภาพจากเอกสาร PDF ในรูปแบบ JPEG และบันทึกไว้ในโฟลเดอร์บนระบบจัดเก็บข้อมูลบนคลาวด์
- ขั้นแรก ให้สร้างอินสแตนซ์ของคลาส ApiClient โดยระบุรหัสไคลเอนต์และรหัสลับไคลเอนต์เป็นอาร์กิวเมนต์
- ประการที่สอง สร้างอินสแตนซ์ของคลาส PdfApi ซึ่งรับ ApiClient เป็นอาร์กิวเมนต์
- ตอนนี้ เรียกใช้เมธอด putimagesextractasjpeg(…) ซึ่งรับชื่อ PDF อินพุต หมายเลขหน้า PDF ที่เกี่ยวข้อง และพารามิเตอร์เสริมที่ระบุโฟลเดอร์เป้าหมายที่จะบันทึกภาพที่แยกออกมา
def extractImages():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# สร้างอินสแตนซ์ PdfApi ขณะส่ง PdfApiClient เป็นอาร์กิวเมนต์
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'URL2PDF.pdf'
# เรียก API เพื่อแยกภาพเป็น JPEG และบันทึกลงในโฟลเดอร์ ExtractedImages ในที่จัดเก็บข้อมูลบนคลาวด์
response = pdf_api.put_images_extract_as_jpeg(name = input_file, page_number= 3, dest_folder = 'ExtractedImages')
print(response)
# พิมพ์ข้อความในคอนโซล (ทางเลือก)
print('Images successfully extracted from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
API ยังรองรับพารามิเตอร์เสริมสองตัวเพื่อระบุความกว้างและความสูงให้กับรูปภาพที่แยกออกมา

Image 4:- Preview of extracted images.
ในกรณีที่คุณต้องการแยกภาพในรูปแบบอื่น คุณอาจพิจารณาใช้ API ต่อไปนี้:
- PutImagesExtractAsTiff - แยกภาพเอกสารในรูปแบบ TIFF
- PutImagesExtractAsGif - ดึงภาพเอกสารออกมาในรูปแบบ GIF
- PutImagesExtractAsPng - ดึงภาพเอกสารออกมาในรูปแบบ PNG
ดาวน์โหลดรูปภาพ PDF โดยใช้คำสั่ง cURL
การแยกภาพจากไฟล์ PDF สามารถทำได้โดยใช้ Aspose.PDF Cloud API กับคำสั่ง cURL การใช้คำสั่ง cURL ช่วยให้คุณสามารถส่งคำขอ HTTP ไปยังปลายทาง API และแยกภาพจาก PDF ได้อย่างง่ายดาย วิธีนี้ให้ความยืดหยุ่นและสะดวกสบาย เนื่องจากคุณสามารถรวมฟังก์ชันการแยกภาพลงในสคริปต์หรือแอปพลิเคชันของคุณได้โดยตรง นอกจากนี้ คุณยังสามารถเข้าถึง REST API ผ่านเทอร์มินัลบรรทัดคำสั่งบนแพลตฟอร์มใดก็ได้ เช่น Windows, Linux, macOS หรือระบบปฏิบัติการอื่นๆ
ในส่วนนี้ เราจะใช้คำสั่ง cURL เพื่อแยกภาพในรูปแบบ PNG และบันทึกผลลัพธ์ไปยังระบบจัดเก็บข้อมูลบนคลาวด์ ดังนั้น ขั้นตอนแรกคือการสร้าง JSON Web Token (JWT) โดยดำเนินการตามคำสั่งต่อไปนี้
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
ตอนนี้ โปรดดำเนินการคำสั่งต่อไปนี้เพื่อแยกภาพจากหน้าที่ 3 ของเอกสาร PDF เท่านั้น ภาพจะถูกแยกออกมาในรูปแบบ PNG
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/URL2PDF.pdf/pages/3/images/extract/png?width=0&height=0&destFolder=ExtractedImages" \
-H "Accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-d{}
ไฟล์ PDF ตัวอย่างที่ใช้ในตัวอย่างข้างต้นสามารถดาวน์โหลดได้จาก URL2PDF.pdf
บทสรุป
โดยสรุป การแยกภาพจากไฟล์ PDF เป็นความสามารถอันมีค่าที่สามารถทำได้โดยใช้ทั้งคำสั่ง Aspose.PDF Cloud SDK สำหรับ Python และ cURL ไม่ว่าคุณจะชอบความสะดวกและความเรียบง่ายของการเขียนโปรแกรม Python หรือความคล่องตัวของคำสั่ง cURL Aspose.PDF Cloud ก็มี API ที่แข็งแกร่งเพื่อบรรลุภารกิจนี้ ด้วยการใช้ประโยชน์จากพลังของคลาวด์ คุณสามารถแยกภาพจากเอกสาร PDF ได้อย่างง่ายดาย ช่วยเพิ่มประสิทธิภาพเวิร์กโฟลว์ของคุณ อย่างไรก็ตาม ด้วย Aspose.PDF Cloud คุณมีความยืดหยุ่นในการเลือกแนวทางที่เหมาะสมที่สุดกับความต้องการของคุณ และผสานรวมฟังก์ชันการแยกภาพเข้ากับโครงการของคุณได้อย่างราบรื่น
แหล่งข้อมูลที่มีประโยชน์
บทความที่เกี่ยวข้อง
เราขอแนะนำให้เยี่ยมชมลิงค์ต่อไปนี้เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับ: