
PDF는 보고서, 프레젠테이션, 브로셔를 포함한 다양한 유형의 문서를 저장하고 공유하는 데 널리 사용됩니다. 그러나 이러한 파일에서 이미지를 추출하는 경우 프로세스가 시간이 많이 걸리고 번거로울 수 있습니다. 추가 편집, 분석 또는 자체 프로젝트에 포함하기 위해 이미지를 추출해야 하는 경우 신뢰할 수 있고 효율적인 접근 방식이 중요합니다. 따라서 프로그래밍 SDK의 기능을 활용하면 이미지 추출 프로세스를 간소화하고 귀중한 시간과 노력을 절약할 수 있습니다. 이제 이 문서에서는 Python Cloud SDK를 사용하여 PDF 파일에서 이미지를 추출하고 완전히 새로운 수준의 생산성과 편의성을 잠금 해제하는 방법에 대한 세부 정보를 살펴보겠습니다.
PDF 처리 클라우드 SDK
Python을 사용하여 PDF 파일에서 이미지를 추출하는 경우 Aspose.PDF Cloud API는 강력하고 다재다능한 도구입니다. Aspose.PDF Cloud SDK for Python을 사용하면 PDF에서 이미지를 추출할 수 있을 뿐만 아니라 PDF를 다른 형식으로 변환하고, 주석을 추가하고, PDF 문서를 병합하거나 분할하는 등 다양한 다른 작업을 수행할 수 있습니다. 게다가 SDK는 PDF 파일을 프로그래밍 방식으로 조작할 수 있는 포괄적인 API 세트를 제공하여 시간과 노력을 절약할 수 있습니다.
이제 SDK를 설치하려면 PIP 또는 GitHub 저장소에서 다운로드하세요. 따라서 시스템에 최신 버전의 SDK를 설치하려면 터미널/명령 프롬프트에서 다음 명령을 실행하세요.
pip install asposepdfcloud
파이참 IDE
PyCharm IDE를 사용하는 경우 SDK를 프로젝트에 종속성으로 직접 추가할 수 있습니다.
파일 ->설정 ->프로젝트 ->Python 인터프리터 ->asposepdfcloud

이미지 1: PyCharm 설정 옵션.

이미지 2: Aspose.PDF 클라우드 Python 패키지.
또 다른 중요한 단계는 GitHub 또는 Google 계정을 사용하여 클라우드 대시보드에서 무료 계정을 만드는 것입니다. 또는 새 계정 만들기 버튼을 클릭하고 필요한 정보를 제공하고 개인화된 클라이언트 자격 증명을 얻으십시오.
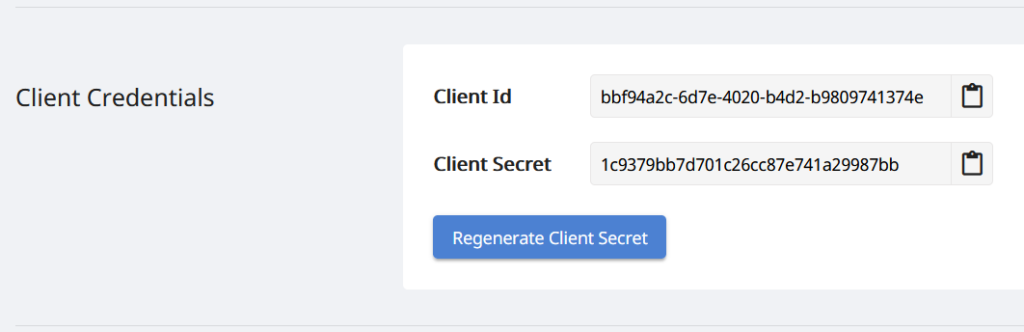
그림 3: 클라우드 대시보드의 클라이언트 자격 증명.
파이썬으로 PDF에서 이미지 추출하기
JPEG 형식의 PDF 문서에서 이미지를 추출하여 클라우드 저장소의 폴더에 저장하려면 아래 단계를 따르세요.
- 먼저 클라이언트 ID와 클라이언트 비밀번호를 인수로 제공하면서 ApiClient 클래스의 인스턴스를 생성합니다.
- 둘째, ApiClient 객체를 인수로 받는 PdfApi 클래스의 인스턴스를 생성합니다.
- 이제 PDF 이름, 해당 PDF 페이지 번호 및 추출된 이미지를 저장할 대상 폴더를 지정하는 선택적 매개변수를 입력으로 받는 putimagesextractasjpeg(…) 메서드를 호출합니다.
def extractImages():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# PdfApiClient를 인수로 전달하면서 PdfApi 인스턴스를 생성합니다.
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'URL2PDF.pdf'
# API를 호출하여 이미지를 JPEG로 추출하고 이를 클라우드 스토리지의 ExtractedImages 폴더에 저장합니다.
response = pdf_api.put_images_extract_as_jpeg(name = input_file, page_number= 3, dest_folder = 'ExtractedImages')
print(response)
# 콘솔에 메시지 출력 (선택 사항)
print('Images successfully extracted from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
API는 추출된 이미지의 너비와 높이를 지정하기 위한 두 가지 선택적 매개변수도 지원합니다.

Image 4:- Preview of extracted images.
다른 형식으로 이미지를 추출해야 하는 경우 다음 API를 사용해 보세요.
- PutImagesExtractAsTiff - TIFF 형식으로 문서 이미지 추출
- PutImagesExtractAsGif - GIF 형식으로 문서 이미지 추출
- PutImagesExtractAsPng - PNG 형식으로 문서 이미지 추출
cURL 명령을 사용하여 PDF 이미지 다운로드
PDF 파일에서 이미지를 추출하는 것은 cURL 명령과 함께 Aspose.PDF Cloud API를 사용하여 달성할 수도 있습니다. cURL 명령을 사용하면 API 엔드포인트에 HTTP 요청을 하고 PDF에서 이미지를 쉽게 추출할 수 있습니다. 이 접근 방식은 이미지 추출 기능을 스크립트나 애플리케이션에 직접 통합할 수 있으므로 유연성과 편의성을 제공합니다. 게다가 Windows, Linux, macOS 또는 기타 운영 체제와 같은 모든 플랫폼에서 명령줄 터미널을 통해 REST API에 액세스할 수 있는 기능도 제공합니다.
이 섹션에서는 PNG 형식의 이미지 추출을 위한 cURL 명령을 사용하고 출력을 클라우드 스토리지에 저장합니다. 따라서 첫 번째 단계는 다음 명령을 실행하여 JSON 웹 토큰(JWT)을 생성하는 것입니다.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
이제 다음 명령을 실행하여 PDF 문서의 3번째 페이지에서만 이미지를 추출하세요. 이미지는 PNG 형식으로 추출됩니다.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/URL2PDF.pdf/pages/3/images/extract/png?width=0&height=0&destFolder=ExtractedImages" \
-H "Accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-d{}
위 예에서 사용된 샘플 PDF 파일은 URL2PDF.pdf에서 다운로드할 수 있습니다.
결론
결론적으로, PDF 파일에서 이미지를 추출하는 것은 Aspose.PDF Cloud SDK for Python과 cURL 명령을 모두 사용하여 달성할 수 있는 귀중한 기능입니다. Python 프로그래밍의 편리함과 단순성을 선호하든 cURL 명령의 다양성을 선호하든 Aspose.PDF Cloud는 이 작업을 수행하기 위한 강력한 API를 제공합니다. 클라우드의 힘을 활용하면 PDF 문서에서 이미지를 쉽게 추출하여 워크플로를 개선할 수 있습니다. 그럼에도 불구하고 Aspose.PDF Cloud를 사용하면 요구 사항에 가장 적합한 접근 방식을 선택하고 이미지 추출 기능을 프로젝트에 원활하게 통합할 수 있는 유연성이 있습니다.
유용한 리소스
관련기사
자세한 내용을 알아보려면 다음 링크를 방문해 보세요.