
PDFs are widely used for storing and sharing various types of documents, including reports, presentations, and brochures. However, when it comes to extracting images from these files, the process can be time-consuming and cumbersome. Whether you need to extract images for further editing, analysis, or inclusion in your own projects, having a reliable and efficient approach is crucial. Therefore, leveraging the capabilities of a programming SDK can streamline the image extraction process, saves valuable time and effort. Now in this article, we will explore the details on how to extract images from PDF files using Python Cloud SDK and unlock a whole new level of productivity and convenience.
PDF Processing Cloud SDK
When it comes to extracting images from PDF files using Python, the Aspose.PDF Cloud API is a powerful and versatile tool. With Aspose.PDF Cloud SDK for Python, you can not only extract images from PDFs but also perform various other tasks such as converting PDFs to different formats, adding annotations, merging or splitting PDF documents, and much more. Furthermore, the SDK offers a comprehensive set of APIs that enable you to manipulate PDF files programmatically, saving you time and effort.
Now, in order to install the SDK, please download it from PIP or GitHub repository. So, please execute the following command on the terminal/command prompt to install the latest version of SDK on the system.
pip install asposepdfcloud
PyCharm IDE
If you are using PyCharm IDE, you may directly add the SDK as a dependency in your project.
File -> Settings -> Project -> Python Interpreter -> asposepdfcloud
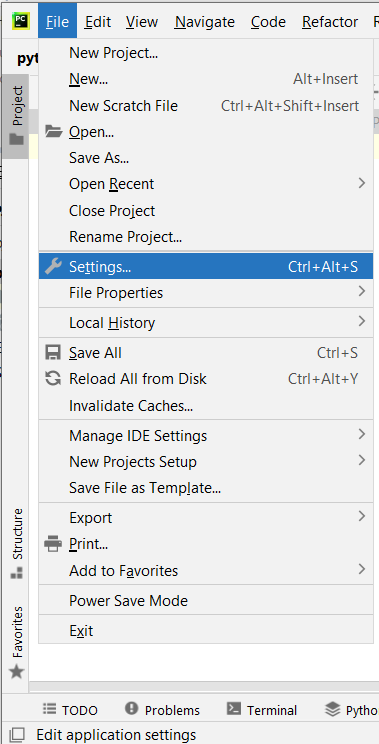
Image 1:- PyCharm settings option.
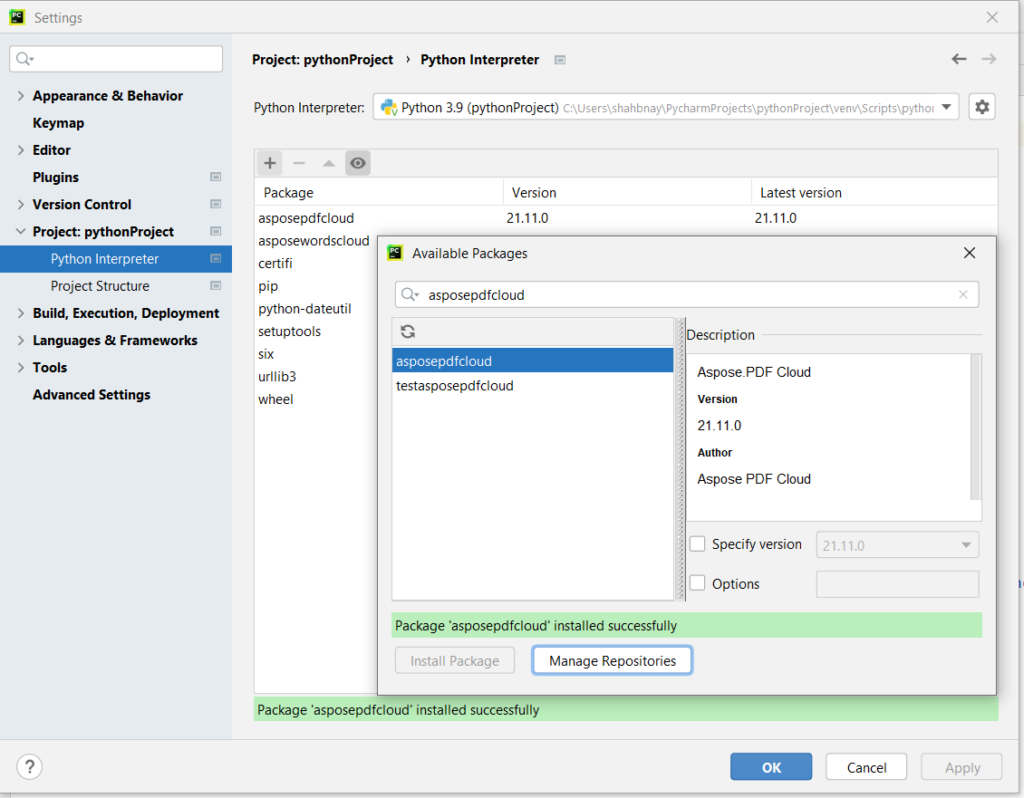
Image 2:- Aspose.PDF Cloud Python Package.
Another important step is to create a free account over cloud dashboard using GitHub or Google account. Or, click create a new account button and provide the required information and obtain your personalized Client Credentials.
c Image 3:- Client Credentials on Cloud dashboard.
Extract Images from PDF in Python
Please follow the steps given below to extract images from PDF documents in JPEG format and save them in the folder on Cloud storage.
- Firstly, create an instance of ApiClient class while providing Client ID Client Secret as arguments.
- Secondly, create an instance of PdfApi class which takes ApiClient object as an argument.
- Now, call the method put_images_extract_as_jpeg(…) which takes input PDF name, respective PDF page number and an optional parameter specifying the target folder to save the extracted images.
The API also supports two optional parameters to specify the Width and Height for the extracted images.
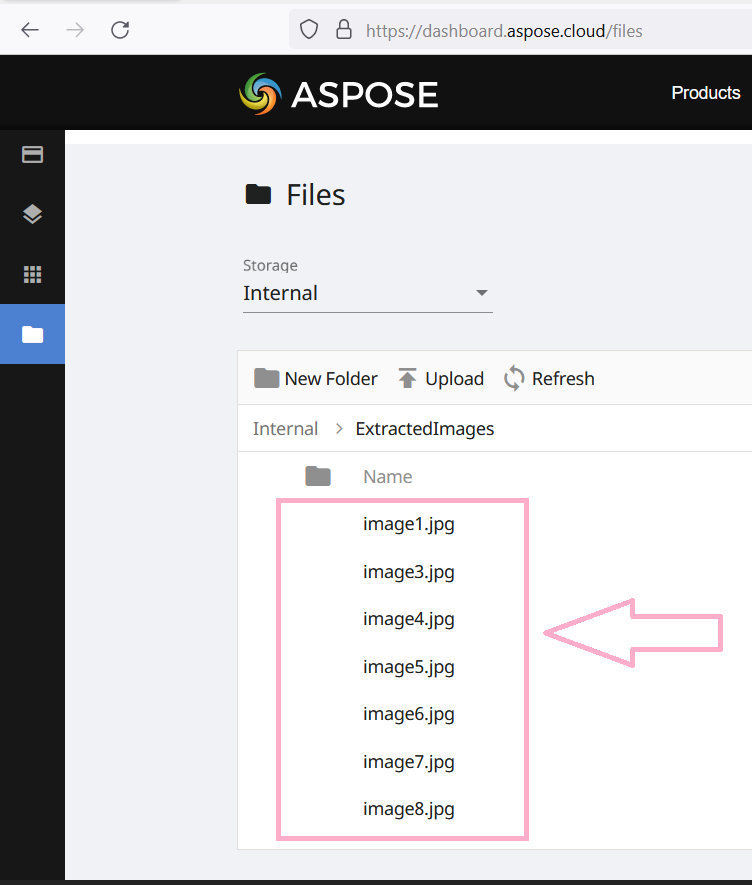
Image 4:- Preview of extracted images.
In case you need to extract images in other formats, you may consider using the following APIs:
- PutImagesExtractAsTiff - Extract document images in TIFF format
- PutImagesExtractAsGif - Extract document images in GIF format
- PutImagesExtractAsPng - Extract document images in PNG format
Download PDF Images using cURL Command
Extracting images from PDF files can also be achieved by using Aspose.PDF Cloud API with cURL commands. By utilizing cURL commands, you can make HTTP requests to the API endpoints and extract images from PDFs with ease. This approach provides flexibility and convenience, as you can integrate the image extraction functionality directly into your scripts or applications. Furthermore, you also get the capabilities to access the REST APIs via command line terminal on any platform i.e. Windows, Linux, macOS, or other operating systems.
In this section, we are going to use the cURL commands for images extraction in PNG format and save the output to Cloud storage. So, the first step is to generate a JSON Web Token (JWT) by executing the following command.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Now, please execute the following command to extract the images only from the 3rd page of the PDF document. The images are extracted in PNG format.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/URL2PDF.pdf/pages/3/images/extract/png?width=0&height=0&destFolder=ExtractedImages" \
-H "Accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-d{}
The sample PDF file used in the above example can be downloaded from URL2PDF.pdf.
Conclusion
In conclusion, extracting images from PDF files is a valuable capability that can be achieved using both the Aspose.PDF Cloud SDK for Python and cURL commands. Whether you prefer the convenience and simplicity of Python programming or the versatility of cURL commands, Aspose.PDF Cloud provides a robust API to accomplish this task. By leveraging the power of the cloud, you can extract images from PDF documents with ease, enhancing your workflow. Nonetheless, with Aspose.PDF Cloud, you have the flexibility to choose the approach that best suits your requirements and seamlessly integrate image extraction functionality into your projects.
Useful Resources
Related Articles
We also recommend visiting the following links to learn more about: