
How to convert PDF to Text in Python
Todays digital world has abundance of information and the ability to extract text from PDF documents has become not just a convenience but a necessity. Imagine you’re sifting through a lengthy PDF file, searching for that critical piece of information to cite in your research, or perhaps you’re managing a repository of documents, seeking to extract data for analysis. In these scenarios and many more, the capability to effortlessly convert PDF content to plain text emerges as a game-changer. This article explores the profound purpose and undeniable benefits of extracting text from PDFs using Python Cloud SDK. This transformation empowers individuals and organizations to efficiently manage, analyze, and utilize digital content in a world where information is of profound importance.
- PDF to Text Conversion REST API
- Extract Text from PDF in Python
- PDF to Text Conversion using cURL Command
PDF to Text Conversion REST API
Achieving text extraction from PDF documents is made seamless and efficient with the Aspose.PDF Cloud SDK for Python. This versatile SDK empowers you to effortlessly convert PDF content into plain text, unlocking the information stored within these digital documents.
The Cloud SDK is available for free download over PIP and GitHub repository. Now execute the following command on the terminal/command prompt to install the latest version of SDK:
pip install asposepdfcloud
If you are using PyCharm IDE, you may directly add the SDK as a dependency in your project.
File -> Settings -> Project -> Python Interpreter -> asposepdfcloud
After the installation, the next major step is a free subscription to our cloud services via Aspose.Cloud dashboard. If you have GitHub or Google account, simply Sign Up or, click on the Create a new Account button. Now login to the dashboard and obtain your personalized Client ID and Client Secret details.
Extract Text from PDF in Python
Please follow the instructions given below to extract Text from PDF documents using Python SDK.
- Firstly, create an instance of ApiClient class while providing Client ID Client Secret as arguments.
- Secondly, create an instance of PdfApi class which takes ApiClient object as an input argument.
- Now call the method get_text(…) while providing LLX, LLY, URX, and URY coordinates.
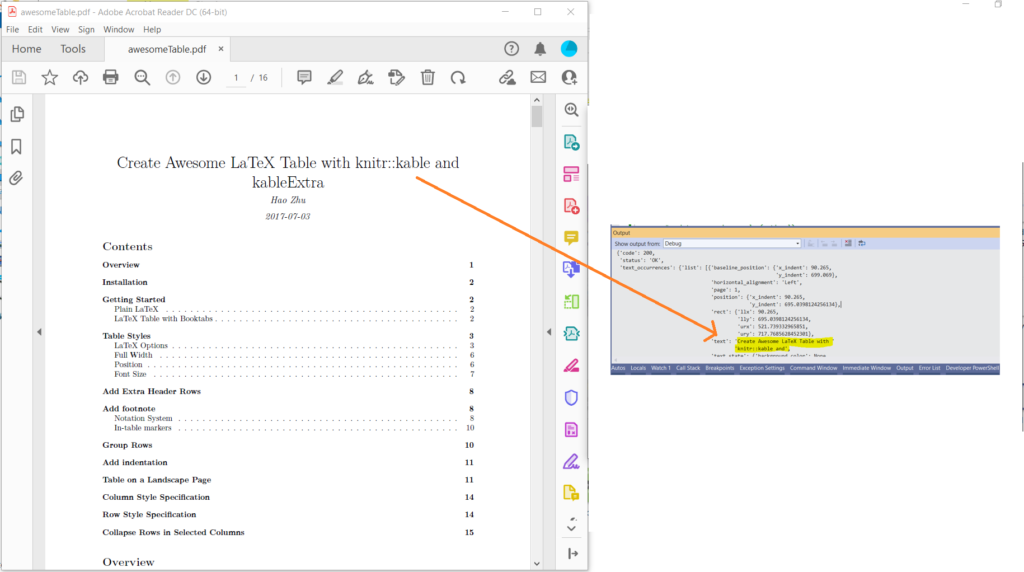
Image 1:- PDF to Text preview.
In case you need to extract the text from a specific page of the document, please try using GetPageText API which takes pageNumber as an argument.
PDF to Text Conversion using cURL Command
Experience the seamless transformation of PDF content into plain text using the powerful combination of Aspose.PDF Cloud and cURL commands. This dynamic integration not only simplifies PDF to text conversion but also offers several benefits that enhance your document management and text extraction experience.
Please note that a pre-requisite under this approach is to generate a JSON Web Token (JWT) based on your client credentials. This step is mandatory as our APIs are only accessible to registered users. Please execute the following command to generate the JWT token.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Once we have the JWT token, we can use the following command to convert PDF to text by extract all textual content. The output is saved as a plain text file on the local drive.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/awesomeTable.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-o Extracted.txt
The sample used in the above example can be downloaded from awesomeTable.pdf.
Conclusion
The extraction of text from PDF documents is a critical requirement in a world awash with digital information. In our exploration of this process, we’ve examined two dynamic pathways: one through the versatile Aspose.PDF Cloud SDK for Python, and the other via the powerful combination of Aspose.PDF Cloud and cURL commands.
Both approaches bridge the gap between static PDF content and dynamic text, enhancing the way we manage, analyze, and utilize digital information. Whether you opt for the sophistication of the SDK or the simplicity of cURL commands, both pathways lead to efficient PDF to text conversion, empowering you to unlock the wealth of textual data hidden within PDF documents.
Related Articles
We also recommend visiting the following links to learn more about: