
Les fichiers PDF sont largement utilisés pour stocker et partager divers types de documents, notamment des rapports, des présentations et des brochures. Cependant, lorsqu’il s’agit d’extraire des images de ces fichiers, le processus peut être long et fastidieux. Que vous ayez besoin d’extraire des images pour les éditer, les analyser ou les inclure dans vos propres projets, il est essentiel d’avoir une approche fiable et efficace. Par conséquent, l’exploitation des capacités d’un SDK de programmation peut rationaliser le processus d’extraction d’images, économiser un temps et des efforts précieux. Dans cet article, nous allons explorer en détail comment extraire des images de fichiers PDF à l’aide de Python Cloud SDK et accéder à un tout nouveau niveau de productivité et de commodité.
- Kit de développement logiciel (SDK) pour le traitement de PDF dans le cloud
- Extraire des images d’un PDF en Python
- Télécharger des images PDF à l’aide de la commande cURL
Kit de développement logiciel (SDK) pour le traitement de PDF dans le cloud
Lorsqu’il s’agit d’extraire des images de fichiers PDF à l’aide de Python, l’Aspose.PDF Cloud API est un outil puissant et polyvalent. Avec Aspose.PDF Cloud SDK for Python, vous pouvez non seulement extraire des images de fichiers PDF, mais également effectuer diverses autres tâches telles que la conversion de PDF en différents formats, l’ajout d’annotations, la fusion ou la division de documents PDF, et bien plus encore. De plus, le SDK offre un ensemble complet d’API qui vous permettent de manipuler des fichiers PDF par programmation, ce qui vous fait gagner du temps et des efforts.
Pour installer le SDK, téléchargez-le à partir du référentiel PIP ou GitHub. Exécutez la commande suivante sur le terminal/l’invite de commande pour installer la dernière version du SDK sur le système.
pip install asposepdfcloud
IDE PyCharm
Si vous utilisez PyCharm IDE, vous pouvez ajouter directement le SDK en tant que dépendance dans votre projet.
Fichier ->Paramètres ->Projet ->Interpréteur Python ->asposepdfcloud
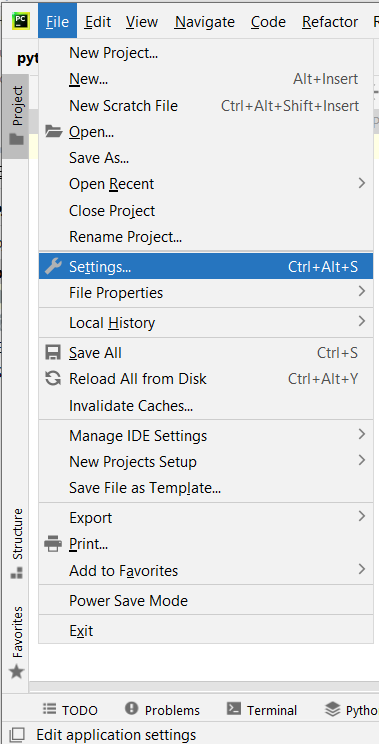
Image 1 : Option de paramètres PyCharm.
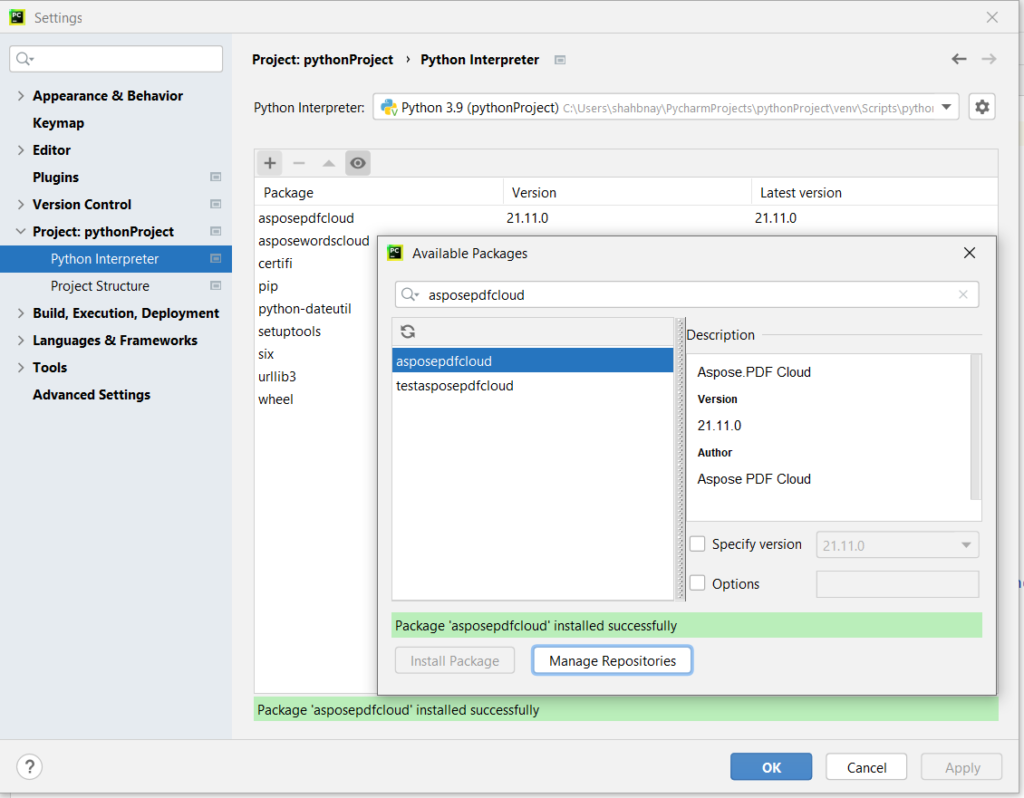
Image 2 : Package Python Cloud Aspose.PDF.
Une autre étape importante consiste à créer un compte gratuit sur cloud dashboard en utilisant GitHub ou un compte Google. Ou cliquez sur le bouton créer un nouveau compte et fournissez les informations requises pour obtenir vos identifiants client personnalisés.
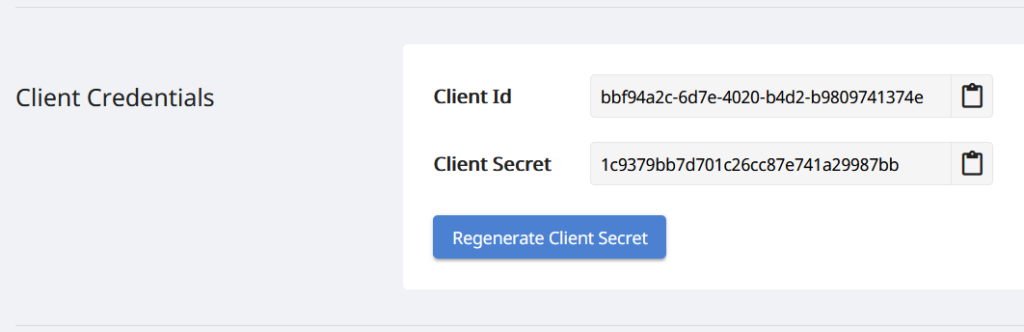
Image 3 : Informations d’identification du client sur le tableau de bord Cloud.
Extraire des images d’un PDF en Python
Veuillez suivre les étapes ci-dessous pour extraire des images de documents PDF au format JPEG et les enregistrer dans le dossier sur le stockage Cloud.
- Tout d’abord, créez une instance de la classe ApiClient tout en fournissant l’ID client et le secret client comme arguments.
- Deuxièmement, créez une instance de la classe PdfApi qui prend l’objet ApiClient comme argument.
- Appelez maintenant la méthode putimagesextractasjpeg(…) qui prend le nom du PDF en entrée, le numéro de page PDF correspondant et un paramètre facultatif spécifiant le dossier cible pour enregistrer les images extraites.
def extractImages():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# créer une instance PdfApi en passant PdfApiClient comme argument
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'URL2PDF.pdf'
# Appelez l'API pour extraire les images au format JPEG et les enregistrer dans le dossier ExtractedImages du stockage Cloud
response = pdf_api.put_images_extract_as_jpeg(name = input_file, page_number= 3, dest_folder = 'ExtractedImages')
print(response)
# imprimer un message dans la console (facultatif)
print('Images successfully extracted from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
L’API prend également en charge deux paramètres facultatifs pour spécifier la largeur et la hauteur des images extraites.
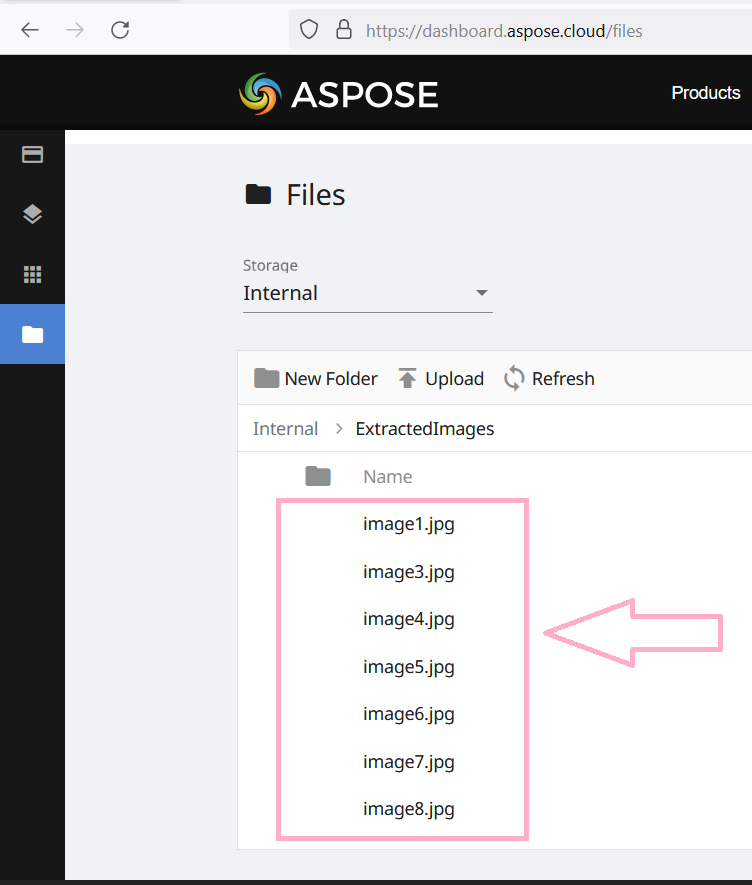
Image 4:- Preview of extracted images.
Si vous avez besoin d’extraire des images dans d’autres formats, vous pouvez envisager d’utiliser les API suivantes :
- PutImagesExtractAsTiff - Extraire les images du document au format TIFF
- PutImagesExtractAsGif - Extraire les images du document au format GIF
- PutImagesExtractAsPng - Extraire les images du document au format PNG
Télécharger des images PDF à l’aide de la commande cURL
L’extraction d’images à partir de fichiers PDF peut également être réalisée en utilisant l’API Cloud Aspose.PDF avec les commandes cURL. En utilisant les commandes cURL, vous pouvez effectuer des requêtes HTTP vers les points de terminaison de l’API et extraire facilement des images à partir de fichiers PDF. Cette approche offre flexibilité et commodité, car vous pouvez intégrer la fonctionnalité d’extraction d’images directement dans vos scripts ou applications. De plus, vous bénéficiez également de la possibilité d’accéder aux API REST via un terminal de ligne de commande sur n’importe quelle plate-forme, c’est-à-dire Windows, Linux, macOS ou d’autres systèmes d’exploitation.
Dans cette section, nous allons utiliser les commandes cURL pour extraire des images au format PNG et enregistrer la sortie sur le stockage Cloud. La première étape consiste donc à générer un jeton Web JSON (JWT) en exécutant la commande suivante.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Maintenant, exécutez la commande suivante pour extraire uniquement les images de la 3ème page du document PDF. Les images sont extraites au format PNG.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/URL2PDF.pdf/pages/3/images/extract/png?width=0&height=0&destFolder=ExtractedImages" \
-H "Accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-d{}
Le fichier PDF d’exemple utilisé dans l’exemple ci-dessus peut être téléchargé à partir de URL2PDF.pdf.
Conclusion
En conclusion, l’extraction d’images à partir de fichiers PDF est une fonctionnalité précieuse qui peut être obtenue à l’aide du SDK Aspose.PDF Cloud pour Python et des commandes cURL. Que vous préfériez la commodité et la simplicité de la programmation Python ou la polyvalence des commandes cURL, Aspose.PDF Cloud fournit une API robuste pour accomplir cette tâche. En exploitant la puissance du cloud, vous pouvez extraire facilement des images à partir de documents PDF, améliorant ainsi votre flux de travail. Néanmoins, avec Aspose.PDF Cloud, vous avez la possibilité de choisir l’approche qui correspond le mieux à vos besoins et d’intégrer de manière transparente la fonctionnalité d’extraction d’images dans vos projets.
Ressources utiles
Articles connexes
Nous vous recommandons également de visiter les liens suivants pour en savoir plus sur :