
PDFs werden häufig zum Speichern und Teilen verschiedener Dokumenttypen verwendet, darunter Berichte, Präsentationen und Broschüren. Das Extrahieren von Bildern aus diesen Dateien kann jedoch zeitaufwändig und umständlich sein. Unabhängig davon, ob Sie Bilder zur weiteren Bearbeitung, Analyse oder Einbindung in Ihre eigenen Projekte extrahieren müssen, ist ein zuverlässiger und effizienter Ansatz von entscheidender Bedeutung. Daher kann die Nutzung der Funktionen eines Programmier-SDK den Bildextraktionsprozess rationalisieren und wertvolle Zeit und Mühe sparen. In diesem Artikel werden wir nun die Details zum Extrahieren von Bildern aus PDF Dateien mithilfe des Python Cloud SDK untersuchen und ein völlig neues Maß an Produktivität und Komfort erreichen.
- PDF Processing Cloud SDK
- Extrahieren Sie Bilder aus PDF in Python
- Laden Sie PDF bilder mit dem cURL-Befehl herunter
PDF Processing Cloud SDK
Wenn es darum geht, Bilder aus PDF Dateien mit Python zu extrahieren, ist die Aspose.PDF Cloud API ein leistungsstarkes und vielseitiges Tool. Mit Aspose.PDF Cloud SDK für Python können Sie nicht nur Bilder aus PDFs extrahieren, sondern auch verschiedene andere Aufgaben ausführen, z. B. PDFs in andere Formate konvertieren, Anmerkungen hinzufügen, PDF Dokumente zusammenführen oder aufteilen und vieles mehr. Darüber hinaus bietet das SDK einen umfassenden Satz von APIs, mit denen Sie PDF Dateien programmgesteuert bearbeiten können, was Ihnen Zeit und Mühe spart.
Um das SDK zu installieren, laden Sie es bitte aus dem PIP oder GitHub-Repository herunter. Führen Sie dann den folgenden Befehl im Terminal/in der Eingabeaufforderung aus, um die neueste Version des SDK auf dem System zu installieren.
pip install asposepdfcloud
PyCharm IDE
Wenn Sie PyCharm IDE verwenden, können Sie das SDK direkt als Abhängigkeit zu Ihrem Projekt hinzufügen.
Datei ->Einstellungen ->Projekt ->Python-Interpreter ->asposepdfcloud
Bild 1: – PyCharm-Einstellungsoption.
Bild 2: – Aspose.PDF Cloud Python-Paket.
Ein weiterer wichtiger Schritt ist die Erstellung eines kostenlosen Kontos über das Cloud Dashboard mithilfe von GitHub oder einem Google-Konto. Alternativ können Sie auf die Schaltfläche Neues Konto erstellen klicken, die erforderlichen Informationen eingeben und Ihre personalisierten Client-Anmeldeinformationen erhalten.
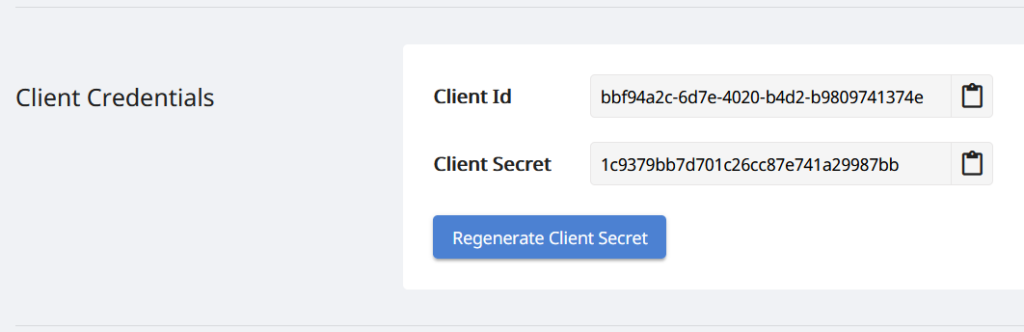
Bild 3: - Client-Anmeldeinformationen auf dem Cloud-Dashboard.
Extrahieren Sie Bilder aus PDF in Python
Befolgen Sie die unten angegebenen Schritte, um Bilder aus PDF Dokumenten im JPEG-Format zu extrahieren und sie im Ordner im Cloud-Speicher zu speichern.
- Erstellen Sie zunächst eine Instanz der Klasse ApiClient und geben Sie als Argumente die Client-ID und das Client-Geheimnis an.
- Zweitens erstellen Sie eine Instanz der PdfApi Klasse, die das ApiClient Objekt als Argument verwendet.
- Rufen Sie nun die Methode putimagesextractasjpeg(…) auf, die den Namen der PDF-Datei, die entsprechende Seitenzahl der PDF-Datei und einen optionalen Parameter übernimmt, der den Zielordner angibt, in dem die extrahierten Bilder gespeichert werden sollen.
def extractImages():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# Erstellen Sie eine PdfApi-Instanz und übergeben Sie dabei PdfApiClient als Argument
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'URL2PDF.pdf'
# Rufen Sie die API auf, um Bilder als JPEG zu extrahieren und sie im Ordner „ExtractedImages“ im Cloud-Speicher zu speichern.
response = pdf_api.put_images_extract_as_jpeg(name = input_file, page_number= 3, dest_folder = 'ExtractedImages')
print(response)
# Nachricht in der Konsole drucken (optional)
print('Images successfully extracted from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
Die API unterstützt auch zwei optionale Parameter zum Festlegen der Breite und Höhe für die extrahierten Bilder.

Image 4:- Preview of extracted images.
Falls Sie Bilder in anderen Formaten extrahieren müssen, können Sie die Verwendung der folgenden APIs in Betracht ziehen:
- PutImagesExtractAsTiff - Extrahiert Dokumentbilder im TIFF-Format
- PutImagesExtractAsGif - Extrahiert Dokumentbilder im GIF-Format
- PutImagesExtractAsPng - Extrahiert Dokumentbilder im PNG-Format
Laden Sie PDF bilder mit dem cURL-Befehl herunter
Das Extrahieren von Bildern aus PDF Dateien kann auch mithilfe der Aspose.PDF Cloud API mit cURL-Befehlen erfolgen. Mithilfe von cURL-Befehlen können Sie HTTP-Anfragen an die API-Endpunkte senden und problemlos Bilder aus PDFs extrahieren. Dieser Ansatz bietet Flexibilität und Komfort, da Sie die Bildextraktionsfunktion direkt in Ihre Skripte oder Anwendungen integrieren können. Darüber hinaus erhalten Sie auch die Möglichkeit, über ein Befehlszeilenterminal auf jeder Plattform, d. h. Windows, Linux, macOS oder anderen Betriebssystemen, auf die REST-APIs zuzugreifen.
In diesem Abschnitt verwenden wir die cURL-Befehle zum Extrahieren von Bildern im PNG-Format und speichern die Ausgabe im Cloud-Speicher. Der erste Schritt besteht also darin, durch Ausführen des folgenden Befehls ein JSON Web Token (JWT) zu generieren.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Führen Sie nun den folgenden Befehl aus, um die Bilder nur von der 3. Seite des PDF Dokuments zu extrahieren. Die Bilder werden im PNG-Format extrahiert.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/URL2PDF.pdf/pages/3/images/extract/png?width=0&height=0&destFolder=ExtractedImages" \
-H "Accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-d{}
Die im obigen Beispiel verwendete Beispiel-PDF-Datei kann von URL2PDF.pdf heruntergeladen werden.
Abschluss
Zusammenfassend lässt sich sagen, dass das Extrahieren von Bildern aus PDF Dateien eine wertvolle Funktion ist, die sowohl mit dem Aspose.PDF Cloud SDK für Python als auch mit cURL-Befehlen erreicht werden kann. Egal, ob Sie die Bequemlichkeit und Einfachheit der Python-Programmierung oder die Vielseitigkeit von cURL-Befehlen bevorzugen, Aspose.PDF Cloud bietet eine robuste API zur Erledigung dieser Aufgabe. Indem Sie die Leistungsfähigkeit der Cloud nutzen, können Sie problemlos Bilder aus PDF Dokumenten extrahieren und so Ihren Arbeitsablauf verbessern. Dennoch haben Sie mit Aspose.PDF Cloud die Flexibilität, den Ansatz zu wählen, der Ihren Anforderungen am besten entspricht, und die Bildextraktionsfunktion nahtlos in Ihre Projekte zu integrieren.
Nützliche Ressourcen
Verwandte Artikel
Wir empfehlen Ihnen außerdem, die folgenden Links zu besuchen, um mehr zu erfahren über: