
Extract text from PDF using .NET REST API.
The PDF documents have become the standard for sharing and exchanging information across various platforms and devices. While PDFs offer a secure and consistent format, extracting essential data from these documents can be a daunting task, especially when dealing with large volumes of information. Whether you need to extract text for analysis, data entry, or content manipulation, a reliable and efficient text extraction solution is crucial. In this article, we delve into the world of extracting text from PDF files using .NET REST API, powered by the robust Aspose.PDF Cloud SDK.
REST API for PDF Processing
Aspose.PDF Cloud SDK for .NET is a robust and user-friendly API that simplifies text extraction from PDFs. One of the standout features of Aspose.PDF Cloud SDK for .NET is its ability to handle complex PDF structures and accurately extract text from documents with diverse layouts. Whether the PDF contains text, images, tables, or other complex elements, the API can intelligently navigate through the document and retrieve the text content with precision. Therefore, the powerful features, accuracy, and ease of integration make it an ideal choice to extract valuable textual data from PDF documents within their .NET applications.
Now, in order to begin with this feature, the first step is to add the reference of Cloud SDK in our .NET solution. So, search Aspose.PDF-Cloud in NuGet packages manager and click the Add Package button. Secondly, visit cloud dashboard and obtain your personalized client credentials.
Extract PDF Text using C# .NET
In this section, we are going to explore the details to extract text from PDF programmatically.
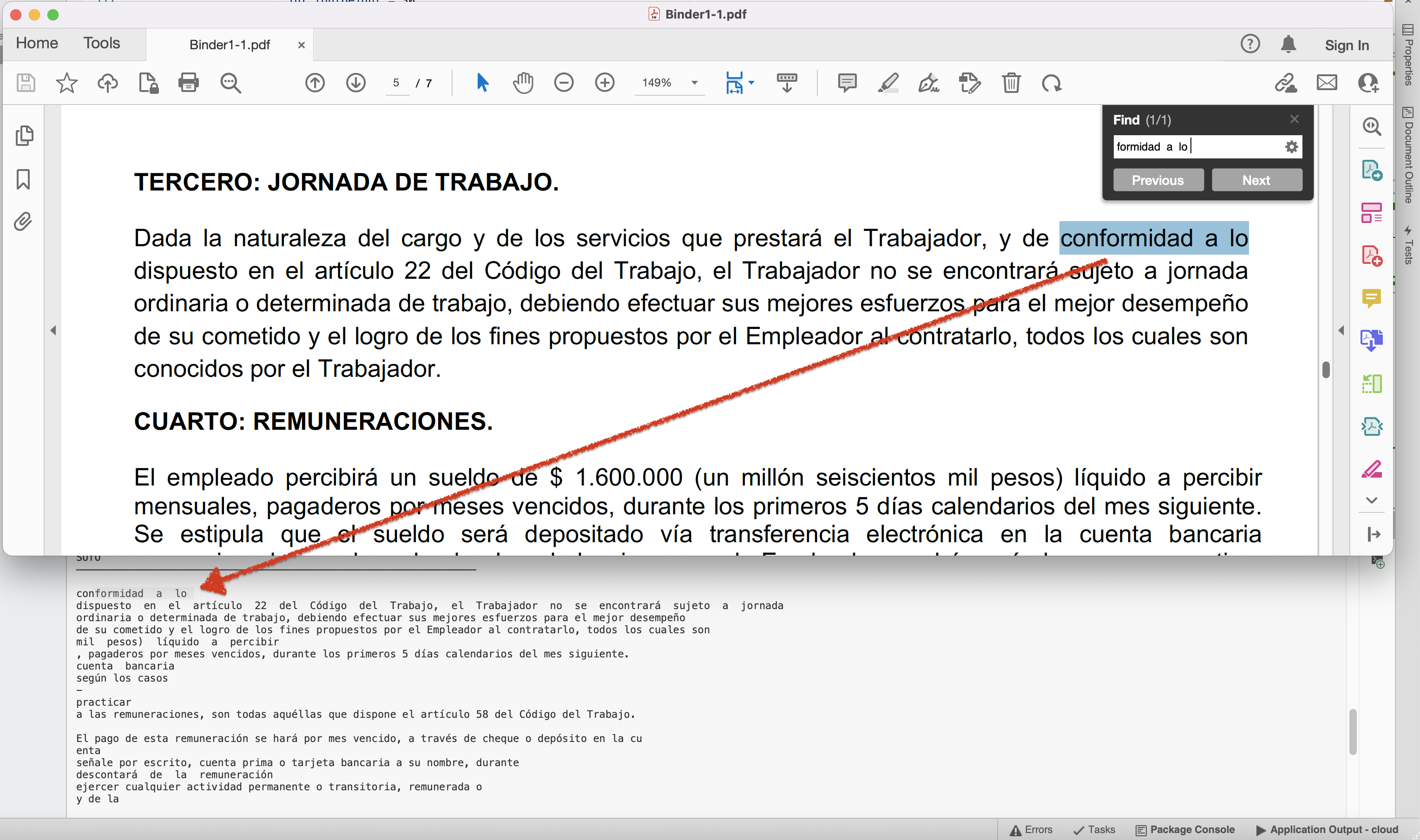
Preview of text pulled from PDF document.
Given below are the details regarding above stated code snippet.
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
Firstly, create an instance of PdfApi class where we pass client credentials as arguments.
String inputFile = "Binder1-1.pdf";
var sourceFile = System.IO.File.OpenRead(inputFile);
Load the content of input PDF file to stream instance.
pdfApi.UploadFile("inputPDF.pdf", sourceFile);
Upload the PDF document to cloud storage.
TextRectsResponse response = pdfApi.GetText("inputPDF.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
Call the API to extract text from PDF file at certain page coordinates.
for (int counter = 0; counter <= response.TextOccurrences.List.Count - 1; counter++)
{
// write text content in console
Console.WriteLine(response.TextOccurrences.List[counter].Text);
}
Iterate through the list containing extracted text occurrences and print the text instances in console.
Parse Text from PDF using cURL Commands
Using cURL commands in combination with Aspose.PDF Cloud API, you can effortlessly extract text content from PDF files hosted on the cloud storage. The API supports a variety of parameters to customize the extraction process, allowing you to specify coordinates, and other options to extract text with precision.
The first step with this approach is to generate a JWT access token while executing the following command.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Once the JWT token has been generated, please execute the following command to pull the text from the PDF document.
curl -v "https://api.aspose.cloud/v3.0/pdf/{inputPDF}/text?splitRects=true&LLX=10&LLY=10&URX=800&URY=800" \
-X GET \
-H "accept: application/json" \
-H "authorization: Bearer {accessToken}" \
-o "extractedContent.txt"
Replace inputPDF with the name of the PDF document already available in cloud storage, and accessToken with JWT token generated above.
Conclusion
In conclusion, both the Aspose.PDF Cloud SDK for .NET and the cURL command approach offer efficient and reliable solutions for extracting text from PDF documents. The Aspose.PDF Cloud SDK for .NET provides a comprehensive and developer-friendly API with a wide range of features, making it a powerful choice for integrating PDF text extraction into .NET applications. On the other hand, the cURL command approach offers a flexible and platform-independent method to interact with the Aspose.PDF Cloud API, making it an excellent option for developers working in different environments and programming languages.
Useful Links
Related Articles
We highly recommend visiting the following blogs: