
Extraia texto de PDF usando a API .NET REST.
Os documentos PDF tornaram-se o padrão para compartilhamento e troca de informações em diversas plataformas e dispositivos. Embora os PDFs ofereçam um formato seguro e consistente, extrair dados essenciais desses documentos pode ser uma tarefa difícil, especialmente quando se lida com grandes volumes de informações. Se você precisa extrair texto para análise, entrada de dados ou manipulação de conteúdo, uma solução de extração de texto confiável e eficiente é crucial. Neste artigo, nos aprofundamos no mundo da extração de texto de arquivos PDF usando a API .NET REST, desenvolvida pelo robusto Aspose.PDF Cloud SDK.
- API REST para processamento de PDF
- Extraia texto PDF usando C# .NET
- Analisar texto de PDF usando comandos cURL
API REST para processamento de PDF
Aspose.PDF Cloud SDK for .NET é uma API robusta e fácil de usar que simplifica a extração de texto de PDFs. Um dos recursos de destaque do Aspose.PDF Cloud SDK para .NET é sua capacidade de lidar com estruturas PDF complexas e extrair com precisão texto de documentos com diversos layouts. Quer o PDF contenha texto, imagens, tabelas ou outros elementos complexos, a API pode navegar de forma inteligente pelo documento e recuperar o conteúdo do texto com precisão. Portanto, os recursos poderosos, a precisão e a facilidade de integração tornam-no a escolha ideal para extrair dados textuais valiosos de documentos PDF em seus aplicativos .NET.
Agora, para começar com esse recurso, o primeiro passo é adicionar a referência do Cloud SDK em nossa solução .NET. Portanto, pesquise Aspose.PDF-Cloud no gerenciador de pacotes NuGet e clique no botão Adicionar pacote. Em segundo lugar, visite cloud dashboard e obtenha suas credenciais de cliente personalizadas.
Extraia texto PDF usando C# .NET
Nesta seção, exploraremos os detalhes para extrair texto de PDF programaticamente.
// Para exemplos completos e arquivos de dados, acesse
https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-dotnet
// Obtenha credenciais do cliente em https://dashboard.aspose.cloud/
string clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
string clientID = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
// crie uma instância do PdfApi
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
// Insira o nome do arquivo PDF
String inputFile = "Binder1-1.pdf";
// Leia o conteúdo do arquivo PDF na instância do stream
var sourceFile = System.IO.File.OpenRead(inputFile);
// Carregar arquivo PDF para armazenamento em nuvem
pdfApi.UploadFile("inputPDF.pdf", sourceFile);
// Coordenada X do canto inferior esquerdo
Double LLX = 500.0;
// Y - coordenada do canto inferior esquerdo.
Double LLY = 500.0;
// X - coordenada do canto superior direito.
Double URX = 800.0;
// Y - coordenada do canto superior direito.
Double URY = 800.0;
// Chame a API para extrair texto de determinadas coordenadas no documento PDF
TextRectsResponse response = pdfApi.GetText("inputPDF.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// Percorrer ocorrências de texto individuais
for (int counter = 0; counter <= response.TextOccurrences.List.Count - 1; counter++)
{
// escrever conteúdo de texto no console
Console.WriteLine(response.TextOccurrences.List[counter].Text);
}
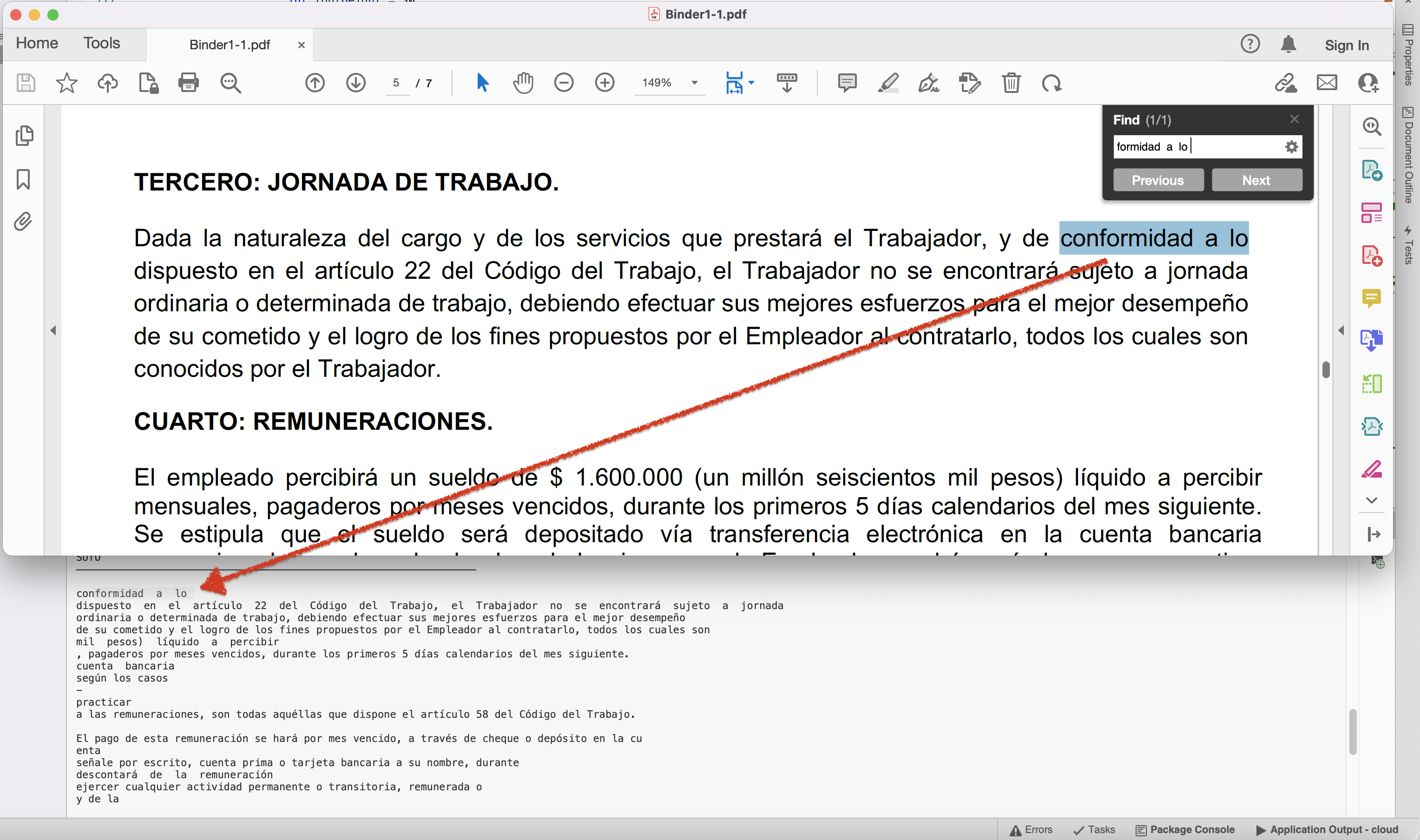
Visualização do texto extraído do documento PDF.
Abaixo estão os detalhes sobre o trecho de código indicado acima.
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
Primeiramente, crie uma instância da classe PdfApi onde passamos as credenciais do cliente como argumentos.
String inputFile = "Binder1-1.pdf";
var sourceFile = System.IO.File.OpenRead(inputFile);
Carregue o conteúdo do arquivo PDF de entrada para a instância de streaming.
pdfApi.UploadFile("inputPDF.pdf", sourceFile);
Carregue o documento PDF para armazenamento em nuvem.
TextRectsResponse response = pdfApi.GetText("inputPDF.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
Chame a API para extrair texto do arquivo PDF em determinadas coordenadas da página.
for (int counter = 0; counter <= response.TextOccurrences.List.Count - 1; counter++)
{
// write text content in console
Console.WriteLine(response.TextOccurrences.List[counter].Text);
}
Itere pela lista que contém ocorrências de texto extraídas e imprima as instâncias de texto no console.
Analisar texto de PDF usando comandos cURL
Usando comandos cURL em combinação com a API Aspose.PDF Cloud, você pode extrair facilmente conteúdo de texto de arquivos PDF hospedados no armazenamento em nuvem. A API suporta uma variedade de parâmetros para personalizar o processo de extração, permitindo especificar coordenadas e outras opções para extrair texto com precisão.
A primeira etapa com essa abordagem é gerar um token de acesso JWT ao executar o comando a seguir.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Depois que o token JWT for gerado, execute o seguinte comando para extrair o texto do documento PDF.
curl -v "https://api.aspose.cloud/v3.0/pdf/{inputPDF}/text?splitRects=true&LLX=10&LLY=10&URX=800&URY=800" \
-X GET \
-H "accept: application/json" \
-H "authorization: Bearer {accessToken}" \
-o "extractedContent.txt"
Substitua inputPDF pelo nome do documento PDF já disponível no armazenamento em nuvem e accessToken pelo token JWT gerado acima.
Conclusão
Concluindo, tanto o Aspose.PDF Cloud SDK para .NET quanto a abordagem de comando cURL oferecem soluções eficientes e confiáveis para extrair texto de documentos PDF. O Aspose.PDF Cloud SDK para .NET fornece uma API abrangente e amigável ao desenvolvedor com uma ampla gama de recursos, tornando-o uma escolha poderosa para integrar a extração de texto PDF em aplicativos .NET. Por outro lado, a abordagem de comando cURL oferece um método flexível e independente de plataforma para interagir com a API Aspose.PDF Cloud, tornando-a uma excelente opção para desenvolvedores que trabalham em diferentes ambientes e linguagens de programação.
Links Úteis
Artigos relacionados
É altamente recomendável visitar os seguintes blogs: