
Извлекайте текст из PDF с помощью .NET REST API.
Документы PDF стали стандартом для совместного использования и обмена информацией между различными платформами и устройствами. Хотя PDF-файлы предлагают безопасный и согласованный формат, извлечение важных данных из этих документов может оказаться сложной задачей, особенно при работе с большими объемами информации. Если вам нужно извлечь текст для анализа, ввода данных или манипулирования контентом, надежное и эффективное решение для извлечения текста имеет решающее значение. В этой статье мы углубляемся в мир извлечения текста из PDF-файлов с помощью .NET REST API на базе надежного облачного SDK Aspose.PDF.
- REST API для обработки PDF-файлов
- Извлечение PDF-текста с помощью C# .NET
- Анализ текста из PDF с помощью команд cURL
REST API для обработки PDF-файлов
Aspose.PDF Cloud SDK для .NET — это надежный и удобный API, который упрощает извлечение текста из PDF-файлов. Одной из выдающихся особенностей Aspose.PDF Cloud SDK для .NET является его способность обрабатывать сложные структуры PDF и точно извлекать текст из документов с разнообразными макетами. Независимо от того, содержит ли PDF-файл текст, изображения, таблицы или другие сложные элементы, API может интеллектуально перемещаться по документу и точно получать текстовое содержимое. Таким образом, мощные функции, точность и простота интеграции делают его идеальным выбором для извлечения ценных текстовых данных из документов PDF в приложениях .NET.
Теперь, чтобы начать работу с этой функцией, первым делом нужно добавить ссылку на Cloud SDK в наше решение .NET. Итак, найдите Aspose.PDF-Cloud в диспетчере пакетов NuGet и нажмите кнопку «Добавить пакет». Во-вторых, посетите облачную панель и получите персональные учетные данные клиента.
Извлечение PDF-текста с помощью C# .NET
В этом разделе мы собираемся изучить детали программного извлечения текста из PDF.
// Полные примеры и файлы данных см.
https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-dotnet
// Получите учетные данные клиента с https://dashboard.aspose.cloud/.
string clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
string clientID = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
// создать экземпляр PdfApi
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
// Введите имя PDF-файла
String inputFile = "Binder1-1.pdf";
// Считайте содержимое PDF-файла в экземпляр потока.
var sourceFile = System.IO.File.OpenRead(inputFile);
// Загрузите PDF-файл в облачное хранилище
pdfApi.UploadFile("inputPDF.pdf", sourceFile);
// Координата X нижнего левого угла
Double LLX = 500.0;
// Y - координата нижнего левого угла.
Double LLY = 500.0;
// X - координата правого верхнего угла.
Double URX = 800.0;
// Y - координата правого верхнего угла.
Double URY = 800.0;
// Вызовите API для извлечения текста из определенных координат в PDF-документе.
TextRectsResponse response = pdfApi.GetText("inputPDF.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// Обход отдельных вхождений текста
for (int counter = 0; counter <= response.TextOccurrences.List.Count - 1; counter++)
{
// писать текстовое содержимое в консоли
Console.WriteLine(response.TextOccurrences.List[counter].Text);
}
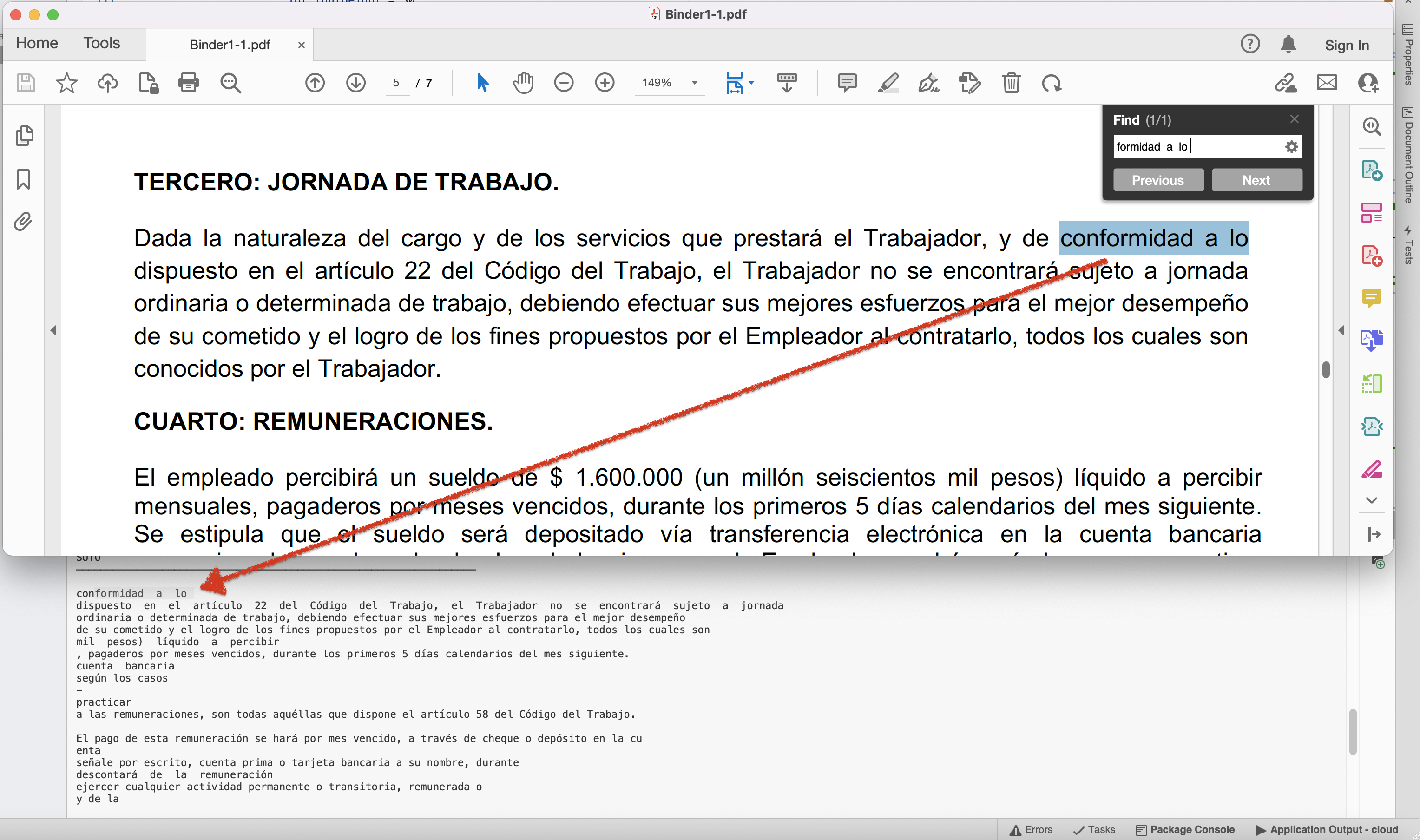
Предварительный просмотр текста, извлеченного из PDF-документа.
Ниже приведены подробности относительно вышеуказанного фрагмента кода.
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
Во-первых, создайте экземпляр класса PdfApi, куда мы передаем учетные данные клиента в качестве аргументов.
String inputFile = "Binder1-1.pdf";
var sourceFile = System.IO.File.OpenRead(inputFile);
Загрузите содержимое входного PDF-файла в экземпляр потоковой передачи.
pdfApi.UploadFile("inputPDF.pdf", sourceFile);
Загрузите PDF-документ в облачное хранилище.
TextRectsResponse response = pdfApi.GetText("inputPDF.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
Вызовите API для извлечения текста из PDF-файла по определенным координатам страницы.
for (int counter = 0; counter <= response.TextOccurrences.List.Count - 1; counter++)
{
// write text content in console
Console.WriteLine(response.TextOccurrences.List[counter].Text);
}
Перейдите по списку, содержащему извлеченные текстовые экземпляры, и распечатайте текстовые экземпляры в консоли.
Анализ текста из PDF с помощью команд cURL
Используя команды cURL в сочетании с облачным API Aspose.PDF, вы можете легко извлекать текстовый контент из файлов PDF, размещенных в облачном хранилище. API поддерживает множество параметров для настройки процесса извлечения, позволяя указывать координаты и другие параметры для точного извлечения текста.
Первым шагом в этом подходе является создание токена доступа JWT при выполнении следующей команды.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
После создания токена JWT выполните следующую команду, чтобы извлечь текст из PDF-документа.
curl -v "https://api.aspose.cloud/v3.0/pdf/{inputPDF}/text?splitRects=true&LLX=10&LLY=10&URX=800&URY=800" \
-X GET \
-H "accept: application/json" \
-H "authorization: Bearer {accessToken}" \
-o "extractedContent.txt"
Замените inputPDF на имя PDF-документа, уже доступного в облачном хранилище, а accessToken на токен JWT, созданный выше.
Заключение
В заключение, как Aspose.PDF Cloud SDK для .NET, так и командный подход cURL предлагают эффективные и надежные решения для извлечения текста из PDF-документов. Aspose.PDF Cloud SDK для .NET предоставляет комплексный и удобный для разработчиков API с широким спектром функций, что делает его мощным выбором для интеграции извлечения текста PDF в приложения .NET. С другой стороны, командный подход cURL предлагает гибкий и независимый от платформы метод взаимодействия с облачным API Aspose.PDF, что делает его отличным вариантом для разработчиков, работающих в разных средах и языках программирования.
Полезные ссылки
Статьи по Теме
Мы настоятельно рекомендуем посетить следующие блоги: