
חלץ טקסט מ-PDF ב-Java
כולנו יודעים שקבצי PDF הם אחד הפורמטים הדיגיטליים החשובים והנפוצים ביותר המשמשים להצגת והחלפת מסמכים בצורה מהימנה, ללא תלות בתוכנה, בחומרה או במערכת ההפעלה. עם זאת, בתרחישים מסוימים, אנו עשויים להיות מעוניינים לקבל קטע מקובצי PDF גדולים. לחלופין, ייתכן שתהיה לנו דרישה לשמור את ה-PDF לטקסט באופן מקוון. אז במאמר זה, אנו הולכים לחקור את הפרטים כיצד לפתח ממיר PDF לטקסט באמצעות Java REST API.
PDF Generator API
קבל את המנוף ליצור מסמכי PDF באמצעות תבניות או מאפס באמצעות REST API שלנו. במקביל, ה-API גם מאפשר לך לערוך כמו גם להפוך את קבצי ה-PDF ל[פורמטים נתמכים] אחרים6. אתה יכול גם לנצל את היתרונות של חילוץ טקסט מ-PDF, פענוח ומיזוג קבצי PDF באמצעות Java Cloud SDK. כעת, על מנת להשתמש ב-Aspose.PDF Cloud SDK עבור Java, עלינו להוסיף את ההתייחסות שלו ליישום Java שלנו על ידי הכללת הפרטים הבאים ב-pom.xml (פרויקט מסוג maven build).
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-cloud-pdf</artifactId>
<version>21.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
לאחר ההתקנה, עלינו ליצור חשבון בחינם באמצעות Cloud Dashboard ולהשיג אישורי לקוח מותאמים אישית.
חלץ טקסט מ-PDF באמצעות Java
בואו נחקור את הפרטים כדי לחלץ טקסט מ-PDF באמצעות Java Cloud SDK. בדוגמה זו, אנו הולכים להשתמש בקלט הבא PdfWithTable.pdf קוֹבֶץ.
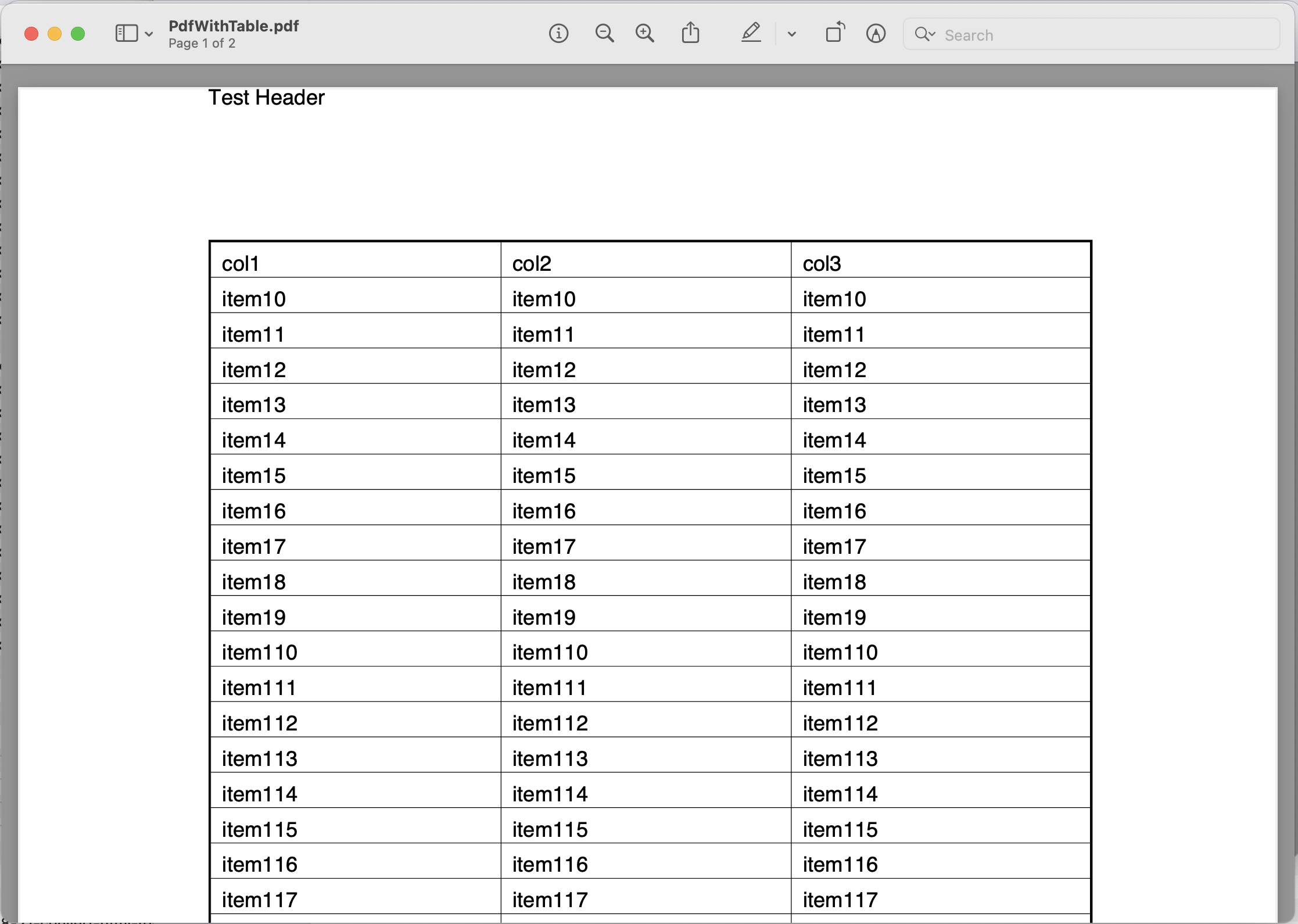
תמונה 1: - קובץ קלט לחילוץ PDF לטקסט.
תמונה 2: - חלץ טקסט מהתצוגה המקדימה של PDF
// לדוגמאות נוספות, בקר בכתובת https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-java/tree/master/Examples/src/main/java/com/aspose/asposecloudpdf/examples
try
{
// קבל ClientID ו-ClientSecret מ-https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// צור מופע של PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// שם מסמך PDF הקלט
String name = "PdfWithTable.pdf";
// קרא את התוכן של קובץ PDF הקלט
File file = new File(name);
// העלה PDF לאחסון בענן
pdfApi.uploadFile("input.pdf", file, null);
// קואורדינטת X של הפינה השמאלית התחתונה
Double LLX = 500.0;
// Y - קואורדינטה של הפינה השמאלית התחתונה.
Double LLY = 500.0;
// X - קואורדינטה של הפינה הימנית העליונה.
Double URX = 800.0;
// Y - קואורדינטה של הפינה הימנית העליונה.
Double URY = 800.0;
// קרא API כדי להמיר PDF לטקסט
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// עברו דרך התרחשות טקסט בודדת
for(int counter=0; counter <=response.getTextOccurrences().getList().size()-1; counter++)
{
// לכתוב תוכן טקסט במסוף
System.out.println(response.getTextOccurrences().getList().get(counter).getText());
}
System.out.println("Extract Text from PDF successful !");
}catch(Exception ex)
{
System.out.println(ex);
}
כעת ננסה להבין את קטע הקוד שצוין לעיל:
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
צור מופע של PdfApi תוך העברת האישורים המותאמים אישית כטיעונים.
File file = new File(name);
pdfApi.uploadFile("input.pdf", file, null);
קרא את ה-PDF הקלט באמצעות אובייקט File והעלה אותו לאחסון בענן באמצעות שיטת uploadFile(…) של המחלקה PdfAPi. שימו לב שהקובץ מועלה עם השם המשמש בשיטת uploadFile.
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
כעת קראו לשיטת getText(..) שבה אנו מציינים את שם קובץ ה-PDF הקלט, מידות מלבניות בעמוד שממנו עלינו לחלץ את התוכן הטקסטואלי, ולהחזיר את התוכן שחולץ לאובייקט TextRectsResponse.
response.getTextOccurrences().getList().get(counter).getText()
לבסוף, על מנת להדפיס את תוכן הטקסט שחולץ, אנו הולכים לחזור על כל ה- TextOccurances ולהציג אותם במסוף.
PDF לטקסט באמצעות פקודות cURL
מלבד קטע קוד Java, אנו יכולים גם לבצע פעולת pdftotext באמצעות פקודות cURL. כעת, אחד התנאים המוקדמים לגישה זו הוא ליצור אסימון גישה ל-JWT (בהתבסס על אישורי לקוח) באמצעות הפקודה הבאה.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
לאחר יצירת ה-JWT, אנא בצע את הפקודה הבאה כדי לחלץ טקסט מקובץ ה-PDF שכבר זמין באחסון בענן.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/input.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
טיפ מהיר
מחפש אפליקציית PDF לטקסט בחינם! נסה להשתמש במנתח PDF.
הערות לסיום
לסיכום, חילוץ טקסט מקובצי PDF באמצעות Java יכול להיות פתרון רב עוצמה עבור אלה המעוניינים להפוך את צרכי עיבוד הנתונים והניתוח שלהם לאוטומטיים. בעזרת מדריך זה, כעת יש לך בסיס איתן להתבסס עליו ותוכל ליישם בקלות פתרון משלך מבוסס Java עבור חילוץ טקסט ממסמכי PDF. בין אם אתה מחפש לחלץ טקסט לניתוח נתונים, למידת מכונה או כל מטרה אחרת, Java מספקת פלטפורמה גמישה ואמינה לצרכים שלך. אז קדימה, העמד את הכישורים החדשים שלך למבחן!
אם אתה מעוניין לחקור תכונות מרגשות אחרות המוצעות על ידי ה-API, אנא עיין בתיעוד המוצר. לבסוף, אם אתה נתקל בבעיה כלשהי בזמן השימוש ב-API, או שיש לך שאילתה קשורה כלשהי, אנא אל תהסס לפנות אלינו דרך [פורום תמיכת מוצרים] ללא תשלום 9.
מאמרים קשורים
אנא בקר בקישורים הבאים כדי ללמוד עוד על: