
Extraer texto de PDF en Java
Todos sabemos que los archivos PDF son uno de los formatos digitales más importantes y ampliamente utilizados para presentar e intercambiar documentos de manera confiable, independientemente del software, el hardware o el sistema operativo. Sin embargo, en algunos escenarios, podríamos estar interesados en obtener un extracto de archivos PDF de gran tamaño. O bien, es posible que tengamos un requisito para guardar el PDF en texto en línea. Entonces, en este artículo, vamos a explorar los detalles sobre cómo desarrollar un convertidor de PDF a texto utilizando la API REST de Java.
API del generador de PDF
Obtenga el apalancamiento para generar documentos PDF usando plantillas o desde cero usando nuestra API REST. Al mismo tiempo, la API también le permite editar y transformar los archivos PDF a otros formatos admitidos. También puede aprovechar los beneficios de extraer texto de PDF, descifrar y fusionar archivos PDF con Java Cloud SDK. Ahora, para usar Aspose.PDF Cloud SDK for Java, debemos agregar su referencia en nuestra aplicación Java incluyendo los siguientes detalles en pom.xml (proyecto de tipo de compilación maven).
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-cloud-pdf</artifactId>
<version>21.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
Después de la instalación, debemos crear una cuenta gratuita en Cloud Dashboard y obtener credenciales de cliente personalizadas.
Extraer texto de PDF usando Java
Exploremos los detalles para extraer texto de un PDF usando el SDK de la nube de Java. En este ejemplo, vamos a utilizar la siguiente entrada PdfWithTable.pdf expediente.
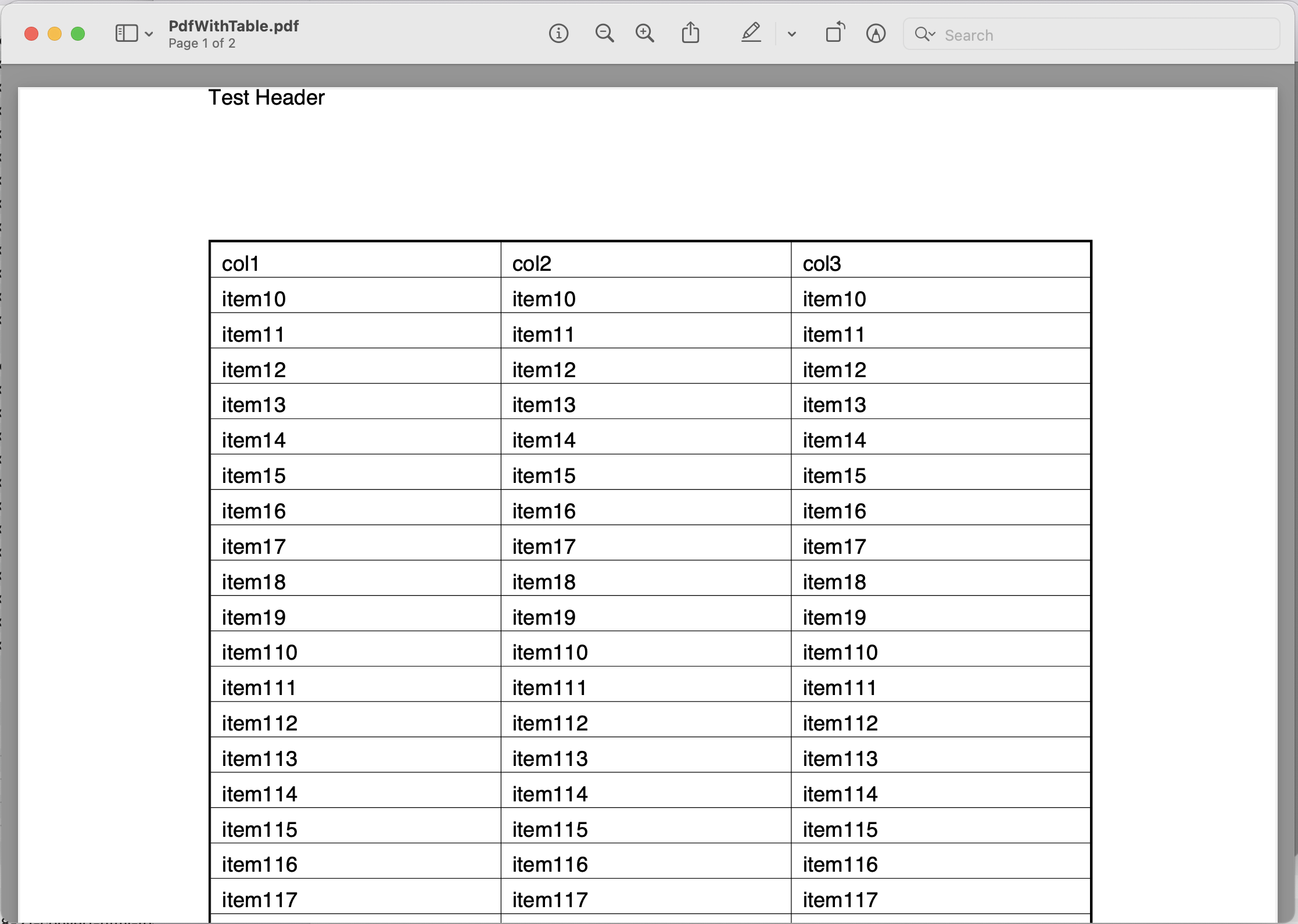
Imagen 1: - Archivo de entrada para la extracción de PDF a texto.
Imagen 2: - Extraer texto de la vista previa de PDF
// para obtener más ejemplos, visite https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-java/tree/master/Examples/src/main/java/com/aspose/asposecloudpdf/examples
try
{
// Obtenga ClientID y ClientSecret de https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// crear una instancia de PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// nombre del documento PDF de entrada
String name = "PdfWithTable.pdf";
// leer el contenido del archivo PDF de entrada
File file = new File(name);
// subir PDF al almacenamiento en la nube
pdfApi.uploadFile("input.pdf", file, null);
// Coordenada X de la esquina inferior izquierda
Double LLX = 500.0;
// Y - coordenada de la esquina inferior izquierda.
Double LLY = 500.0;
// X - coordenada de la esquina superior derecha.
Double URX = 800.0;
// Y - coordenada de la esquina superior derecha.
Double URY = 800.0;
// llame a la API para convertir PDF a texto
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// Recorrer a través de ocurrencias de texto individuales
for(int counter=0; counter <=response.getTextOccurrences().getList().size()-1; counter++)
{
// escribir contenido de texto en la consola
System.out.println(response.getTextOccurrences().getList().get(counter).getText());
}
System.out.println("Extract Text from PDF successful !");
}catch(Exception ex)
{
System.out.println(ex);
}
Ahora intentemos comprender el fragmento de código especificado anteriormente:
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
Cree una instancia de PdfApi mientras pasa las credenciales personalizadas como argumentos.
File file = new File(name);
pdfApi.uploadFile("input.pdf", file, null);
Lea el PDF de entrada usando el objeto File y cárguelo en el almacenamiento en la nube usando el método uploadFile(…) de la clase PdfAPi. Tenga en cuenta que el archivo se carga con el nombre utilizado en el método uploadFile.
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
Ahora llame al método getText(..) donde especificamos el nombre del archivo PDF de entrada, las dimensiones rectangulares en la página de la que necesitamos extraer el contenido textual y devolver el contenido extraído al objeto TextRectsResponse.
response.getTextOccurrences().getList().get(counter).getText()
Finalmente, para imprimir el contenido de texto extraído, vamos a iterar a través de todas las TextOccurances y mostrarlas en la consola.
PDF a texto usando comandos cURL
Además del fragmento de código de Java, también podemos realizar la operación de pdftotext usando los comandos cURL. Ahora, uno de los requisitos previos para este enfoque es generar un token de acceso JWT (basado en las credenciales del cliente) mediante el siguiente comando.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Una vez que se genera el JWT, ejecute el siguiente comando para extraer el texto del archivo PDF que ya está disponible en el almacenamiento en la nube.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/input.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Consejo rapido
¡Busca una aplicación gratuita de PDF a texto! Intente utilizar nuestro [analizador de PDF] (https://products.aspose.app/pdf/parser).
Observaciones finales
En conclusión, extraer texto de archivos PDF usando Java puede ser una solución poderosa para aquellos que buscan automatizar sus necesidades de procesamiento y análisis de datos. Con la ayuda de esta guía, ahora tiene una base sólida sobre la cual construir y puede implementar fácilmente su propia solución basada en Java para la extracción de texto de documentos PDF. Ya sea que esté buscando extraer texto para análisis de datos, aprendizaje automático o cualquier otro propósito, Java proporciona una plataforma flexible y confiable para sus necesidades. ¡Así que adelante y ponga a prueba sus habilidades recién adquiridas!
Si está interesado en explorar otras características interesantes que ofrece la API, explore la Documentación del producto. Por último, si encuentra algún problema al usar la API, o si tiene alguna consulta relacionada, no dude en comunicarse con nosotros a través del Foro de soporte de productos gratuito.
Artículos relacionados
Visite los siguientes enlaces para obtener más información sobre: