
Java의 PDF에서 텍스트 추출
우리 모두는 PDF 파일이 소프트웨어, 하드웨어 또는 운영 체제와 독립적으로 안정적으로 문서를 표시하고 교환하는 데 사용되는 가장 중요하고 널리 사용되는 디지털 형식 중 하나라는 것을 알고 있습니다. 그러나 일부 시나리오에서는 대용량 PDF 파일에서 발췌하는 데 관심이 있을 수 있습니다. 또는 온라인에서 PDF를 텍스트로 저장해야 하는 요구 사항이 있을 수 있습니다. 따라서 이 기사에서는 Java REST API를 사용하여 PDF를 텍스트로 변환하는 변환기를 개발하는 방법에 대한 세부 정보를 살펴보겠습니다.
PDF 생성기 API
템플릿을 사용하거나 REST API를 사용하여 처음부터 PDF 문서를 생성할 수 있습니다. 동시에 API를 사용하면 PDF 파일을 편집하고 다른 지원되는 형식으로 변환할 수도 있습니다. Java Cloud SDK를 사용하여 PDF에서 텍스트 추출, PDF 파일 해독 및 병합의 이점을 누릴 수도 있습니다. 이제 Aspose.PDF Cloud SDK for Java를 사용하려면 pom.xml(maven 빌드 유형 프로젝트)에 다음 세부 정보를 포함하여 Java 애플리케이션에 해당 참조를 추가해야 합니다.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-cloud-pdf</artifactId>
<version>21.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
설치 후 클라우드 대시보드를 통해 무료 계정을 만들고 개인화된 클라이언트 자격 증명을 받아야 합니다.
Java를 사용하여 PDF에서 텍스트 추출
Java 클라우드 SDK를 사용하여 PDF에서 텍스트를 추출하는 세부 사항을 살펴보겠습니다. 이 예에서는 PdfWithTable.pdf 입력을 사용합니다. 파일.
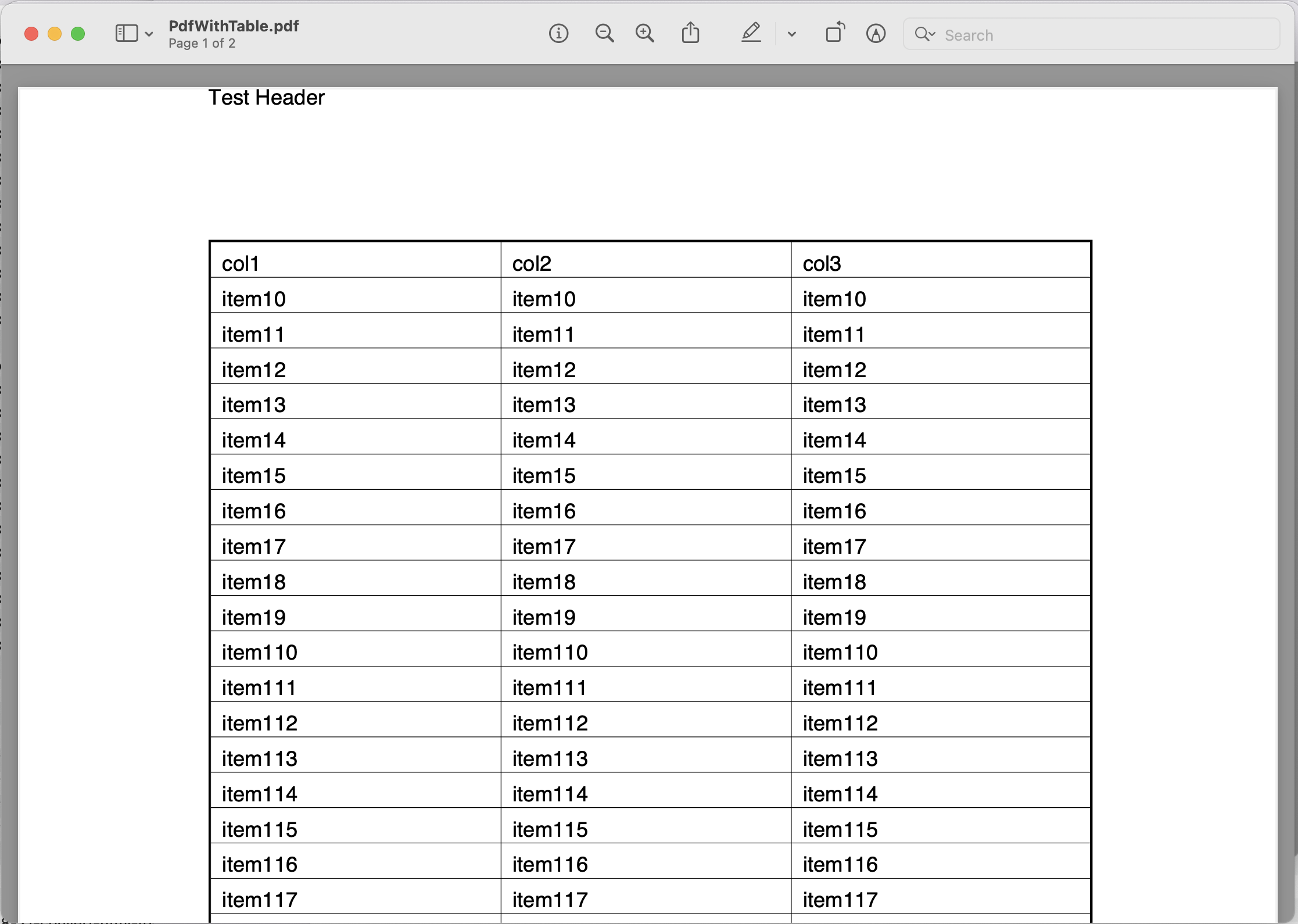
이미지 1:- PDF를 텍스트로 추출하기 위한 입력 파일.
이미지 2:- PDF 미리보기에서 텍스트 추출
// 더 많은 예제를 보려면 https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-java/tree/master/Examples/src/main/java/com/aspose/asposecloudpdf/examples를 방문하십시오.
try
{
// https://dashboard.aspose.cloud/에서 ClientID 및 ClientSecret 가져오기
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// PdfApi 인스턴스 생성
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// 입력 PDF 문서의 이름
String name = "PdfWithTable.pdf";
// 입력된 PDF 파일의 내용 읽기
File file = new File(name);
// 클라우드 스토리지에 PDF 업로드
pdfApi.uploadFile("input.pdf", file, null);
// 아래쪽 - 왼쪽 모서리의 X 좌표
Double LLX = 500.0;
// Y - 왼쪽 하단 모서리의 좌표입니다.
Double LLY = 500.0;
// X - 오른쪽 위 모서리의 좌표입니다.
Double URX = 800.0;
// Y - 오른쪽 위 모서리의 좌표입니다.
Double URY = 800.0;
// PDF를 텍스트로 변환하는 API 호출
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// 개별 텍스트 발생을 통한 트래버스
for(int counter=0; counter <=response.getTextOccurrences().getList().size()-1; counter++)
{
// 콘솔에 텍스트 콘텐츠 쓰기
System.out.println(response.getTextOccurrences().getList().get(counter).getText());
}
System.out.println("Extract Text from PDF successful !");
}catch(Exception ex)
{
System.out.println(ex);
}
이제 위에 지정된 코드 스니펫을 이해해 보겠습니다.
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
개인화된 자격 증명을 인수로 전달하는 동안 PdfApi 인스턴스를 만듭니다.
File file = new File(name);
pdfApi.uploadFile("input.pdf", file, null);
File 객체를 사용하여 입력된 PDF를 읽고 PdfAPi 클래스의 uploadFile(…) 메서드를 사용하여 클라우드 스토리지에 업로드합니다. 파일은 uploadFile 메서드에서 사용한 이름으로 업로드됩니다.
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
이제 getText(..) 메서드를 호출하여 입력 PDF 파일의 이름, 텍스트 콘텐츠를 추출해야 하는 페이지의 직사각형 치수를 지정하고 추출된 콘텐츠를 TextRectsResponse 객체로 반환합니다.
response.getTextOccurrences().getList().get(counter).getText()
마지막으로 추출된 텍스트 콘텐츠를 인쇄하기 위해 모든 TextOccurances를 반복하고 콘솔에 표시합니다.
cURL 명령을 사용하여 PDF를 텍스트로
Java 코드 조각 외에도 cURL 명령을 사용하여 pdftotext 작업을 수행할 수도 있습니다. 이제 이 접근 방식의 전제 조건 중 하나는 다음 명령을 사용하여 JWT 액세스 토큰(클라이언트 자격 증명 기반)을 생성하는 것입니다.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
JWT가 생성되면 다음 명령을 실행하여 이미 클라우드 저장소에 있는 PDF 파일에서 텍스트를 추출하십시오.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/input.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
빠른 팁
PDF to Text 무료 앱을 찾고 있습니다! 당사의 PDF 파서를 사용해 보십시오.
끝 맺는 말
결론적으로 Java를 사용하여 PDF 파일에서 텍스트를 추출하는 것은 데이터 처리 및 분석 요구를 자동화하려는 사람들에게 강력한 솔루션이 될 수 있습니다. 이 가이드의 도움으로 이제 PDF 문서에서 텍스트 추출을 위한 자체 Java 기반 솔루션을 구축하고 쉽게 구현할 수 있는 견고한 기반을 갖게 되었습니다. 데이터 분석, 기계 학습 또는 기타 목적을 위해 텍스트를 추출하려는 경우 Java는 필요에 맞는 유연하고 안정적인 플랫폼을 제공합니다. 그러니 계속해서 새로 습득한 기술을 시험해 보세요!
API에서 제공하는 다른 흥미로운 기능에 관심이 있다면 제품 설명서를 살펴보십시오. 마지막으로 API를 사용하는 동안 문제가 발생하거나 관련 질문이 있는 경우 무료 제품 지원 포럼을 통해 언제든지 문의하십시오.
관련 기사
자세한 내용은 다음 링크를 참조하십시오.