
Extraheer tekst uit PDF in Java
We weten allemaal dat PDF-bestanden een van de belangrijkste en meest gebruikte digitale indelingen zijn die worden gebruikt om documenten betrouwbaar te presenteren en uit te wisselen, onafhankelijk van software, hardware of besturingssysteem. In sommige scenario’s kunnen we echter geïnteresseerd zijn in een uittreksel van grote pdf-bestanden. Of misschien hebben we een vereiste om de PDF naar tekst online op te slaan. Dus in dit artikel gaan we de details verkennen over het ontwikkelen van een PDF naar tekst-converter met behulp van Java REST API.
- PDF Generator-API
- Extraheer tekst uit PDF met behulp van Java
- PDF naar tekst met behulp van cURL-opdrachten
PDF Generator-API
Profiteer van de hefboomwerking om PDF-documenten te genereren met behulp van sjablonen of helemaal opnieuw met onze REST API. Tegelijkertijd stelt de API je ook in staat om de PDF-bestanden te bewerken en om te zetten naar andere ondersteunde formaten. U kunt ook profiteren van het extraheren van tekst uit PDF, het decoderen en samenvoegen van PDF-bestanden met Java Cloud SDK. Om de Aspose.PDF Cloud SDK voor Java te kunnen gebruiken, moeten we de referentie ervan toevoegen aan onze Java-toepassing door de volgende details op te nemen in pom.xml (maven build-type project).
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-cloud-pdf</artifactId>
<version>21.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
Na de installatie moeten we een gratis account aanmaken via Cloud Dashboard en gepersonaliseerde klantreferenties verkrijgen.
Extraheer tekst uit PDF met behulp van Java
Laten we de details bekijken om tekst uit PDF te extraheren met behulp van Java Cloud SDK. In dit voorbeeld gaan we de volgende invoer gebruiken PdfWithTable.pdf het dossier.
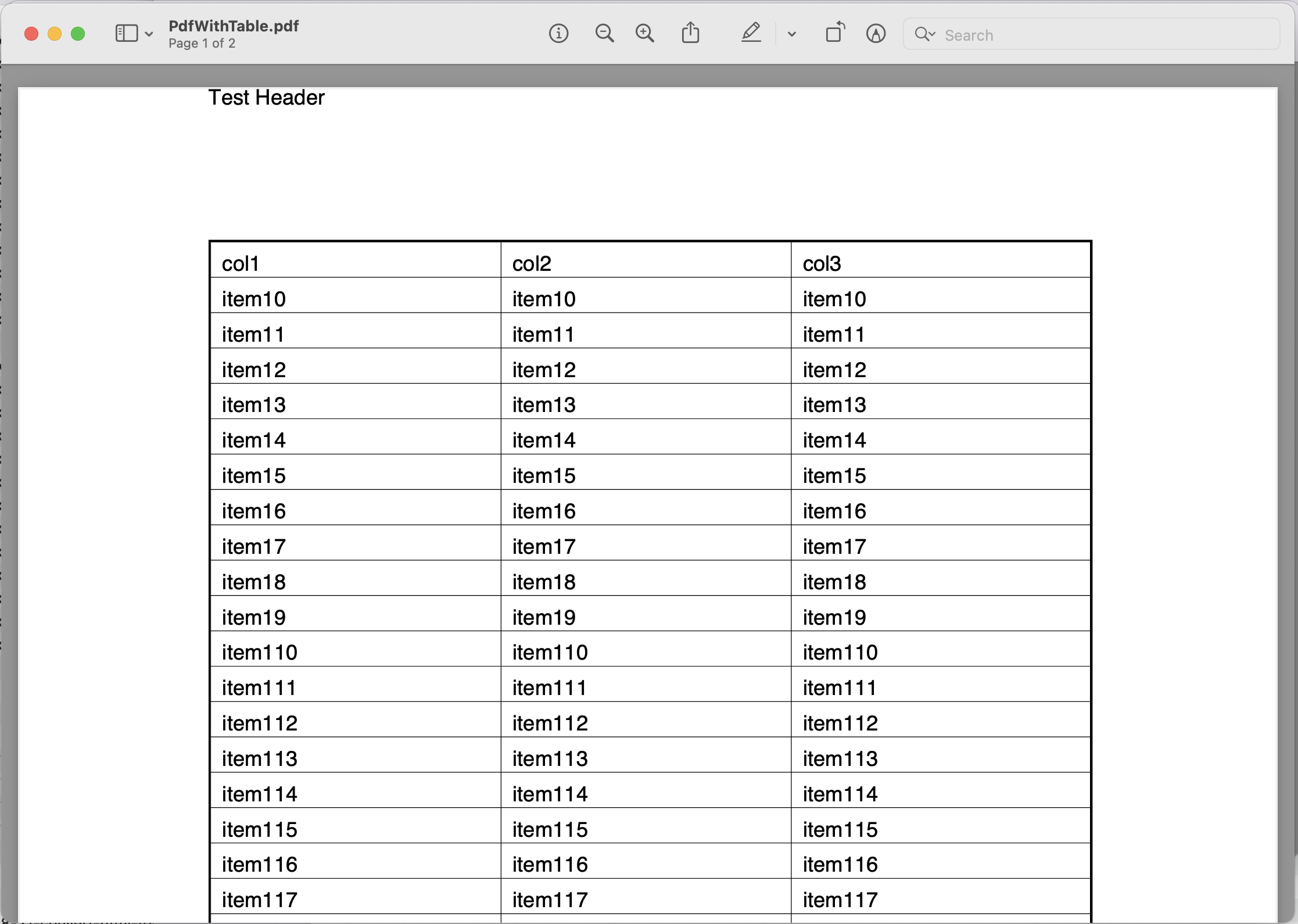
Afbeelding 1:- Invoerbestand voor PDF naar tekstextractie.
Afbeelding 2:- Extraheer tekst uit PDF-voorbeeld
// ga voor meer voorbeelden naar https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-java/tree/master/Examples/src/main/java/com/aspose/asposecloudpdf/examples
try
{
// Haal ClientID en ClientSecret op van https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// maak een instantie van PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// naam van het ingevoerde PDF-document
String name = "PdfWithTable.pdf";
// lees de inhoud van het ingevoerde PDF-bestand
File file = new File(name);
// upload PDF naar cloudopslag
pdfApi.uploadFile("input.pdf", file, null);
// X-coördinaat van linker benedenhoek
Double LLX = 500.0;
// Y - coördinaat van linkerbenedenhoek.
Double LLY = 500.0;
// X - coördinaat van rechterbovenhoek.
Double URX = 800.0;
// Y - coördinaat van de rechterbovenhoek.
Double URY = 800.0;
// bel API om PDF naar tekst te converteren
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// Doorloop individuele tekstgebeurtenissen
for(int counter=0; counter <=response.getTextOccurrences().getList().size()-1; counter++)
{
// schrijf tekstinhoud in de console
System.out.println(response.getTextOccurrences().getList().get(counter).getText());
}
System.out.println("Extract Text from PDF successful !");
}catch(Exception ex)
{
System.out.println(ex);
}
Laten we nu proberen het hierboven gespecificeerde codefragment te begrijpen:
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
Maak een exemplaar van PdfApi terwijl u de gepersonaliseerde inloggegevens als argumenten doorgeeft.
File file = new File(name);
pdfApi.uploadFile("input.pdf", file, null);
Lees de ingevoerde PDF met behulp van het File-object en upload deze naar cloudopslag met behulp van de uploadFile(…)-methode van de PdfAPi-klasse. Houd er rekening mee dat het bestand wordt geüpload met de naam die wordt gebruikt in de uploadFile-methode.
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
Roep nu de methode getText(..) aan, waarbij we de naam van het ingevoerde PDF-bestand specificeren, de rechthoekige afmetingen op de pagina waaruit we de tekstuele inhoud moeten extraheren en de geëxtraheerde inhoud terugsturen naar het TextRectsResponse-object.
response.getTextOccurrences().getList().get(counter).getText()
Ten slotte gaan we, om de geëxtraheerde tekstinhoud af te drukken, alle TextOccurances herhalen en ze in de console weergeven.
PDF naar tekst met behulp van cURL-opdrachten
Behalve Java-codefragmenten kunnen we ook pdftotext-bewerkingen uitvoeren met behulp van cURL-opdrachten. Een van de vereisten voor deze benadering is nu het genereren van een JWT-toegangstoken (op basis van clientreferenties) met behulp van de volgende opdracht.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Zodra de JWT is gegenereerd, voert u de volgende opdracht uit om tekst te extraheren uit het PDF-bestand dat al beschikbaar is in cloudopslag.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/input.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Snelle tip
Op zoek naar PDF naar tekst gratis app! Probeer onze PDF-parser te gebruiken.
Afsluitende opmerkingen
Concluderend kan het extraheren van tekst uit PDF-bestanden met behulp van Java een krachtige oplossing zijn voor diegenen die hun behoeften op het gebied van gegevensverwerking en -analyse willen automatiseren. Met behulp van deze handleiding heeft u nu een solide basis om op voort te bouwen en kunt u eenvoudig uw eigen op Java gebaseerde oplossing voor tekstextractie uit PDF-documenten implementeren. Of u nu tekst wilt extraheren voor gegevensanalyse, machine learning of een ander doel, Java biedt een flexibel en betrouwbaar platform voor uw behoeften. Dus ga je gang en stel je nieuw verworven vaardigheden op de proef!
Als u geïnteresseerd bent in andere opwindende functies die door de API worden aangeboden, bekijk dan de Productdocumentatie. Als je ten slotte een probleem tegenkomt tijdens het gebruik van de API, of als je een gerelateerde vraag hebt, neem dan gerust contact met ons op via het gratis Product Support Forum.
gerelateerde artikelen
Bezoek de volgende links voor meer informatie over: