
Εξαγωγή κειμένου από PDF σε Java
Όλοι γνωρίζουμε ότι τα αρχεία PDF είναι μία από τις πιο σημαντικές και ευρέως χρησιμοποιούμενες ψηφιακές μορφές που χρησιμοποιούνται για την αξιόπιστη παρουσίαση και ανταλλαγή εγγράφων, ανεξάρτητα από λογισμικό, υλικό ή λειτουργικό σύστημα. Ωστόσο, σε ορισμένα σενάρια, μπορεί να μας ενδιαφέρει να λάβουμε ένα απόσπασμα από μεγάλα αρχεία PDF. Εναλλακτικά, μπορεί να απαιτείται η αποθήκευση του PDF σε Κείμενο στο διαδίκτυο. Έτσι, σε αυτό το άρθρο, θα εξερευνήσουμε τις λεπτομέρειες σχετικά με τον τρόπο ανάπτυξης μετατροπέα PDF σε κείμενο χρησιμοποιώντας το Java REST API.
- PDF Generator API
- Εξαγωγή κειμένου από PDF χρησιμοποιώντας Java
- PDF σε κείμενο χρησιμοποιώντας εντολές cURL
PDF Generator API
Αποκτήστε τη δύναμη για τη δημιουργία εγγράφων PDF χρησιμοποιώντας πρότυπα ή από την αρχή χρησιμοποιώντας το REST API. Ταυτόχρονα, το API σάς δίνει επίσης τη δυνατότητα να επεξεργαστείτε καθώς και να μετατρέψετε τα αρχεία PDF σε άλλες υποστηριζόμενες μορφές. Μπορείτε επίσης να επωφεληθείτε από την εξαγωγή κειμένου από PDF, την αποκρυπτογράφηση και τη συγχώνευση αρχείων PDF χρησιμοποιώντας το Java Cloud SDK. Τώρα, για να χρησιμοποιήσουμε το Aspose.PDF Cloud SDK για Java, πρέπει να προσθέσουμε την αναφορά του στην εφαρμογή Java, συμπεριλαμβάνοντας τις ακόλουθες λεπτομέρειες στο pom.xml (έργο τύπου Maven build).
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-cloud-pdf</artifactId>
<version>21.11.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
Μετά την εγκατάσταση, πρέπει να δημιουργήσουμε έναν δωρεάν λογαριασμό μέσω του Cloud Dashboard και να αποκτήσουμε εξατομικευμένα διαπιστευτήρια πελάτη.
Εξαγωγή κειμένου από PDF χρησιμοποιώντας Java
Ας εξερευνήσουμε τις λεπτομέρειες για την εξαγωγή κειμένου από PDF χρησιμοποιώντας το Java cloud SDK. Σε αυτό το παράδειγμα, θα χρησιμοποιήσουμε την ακόλουθη είσοδο PdfWithTable.pdf αρχείο.
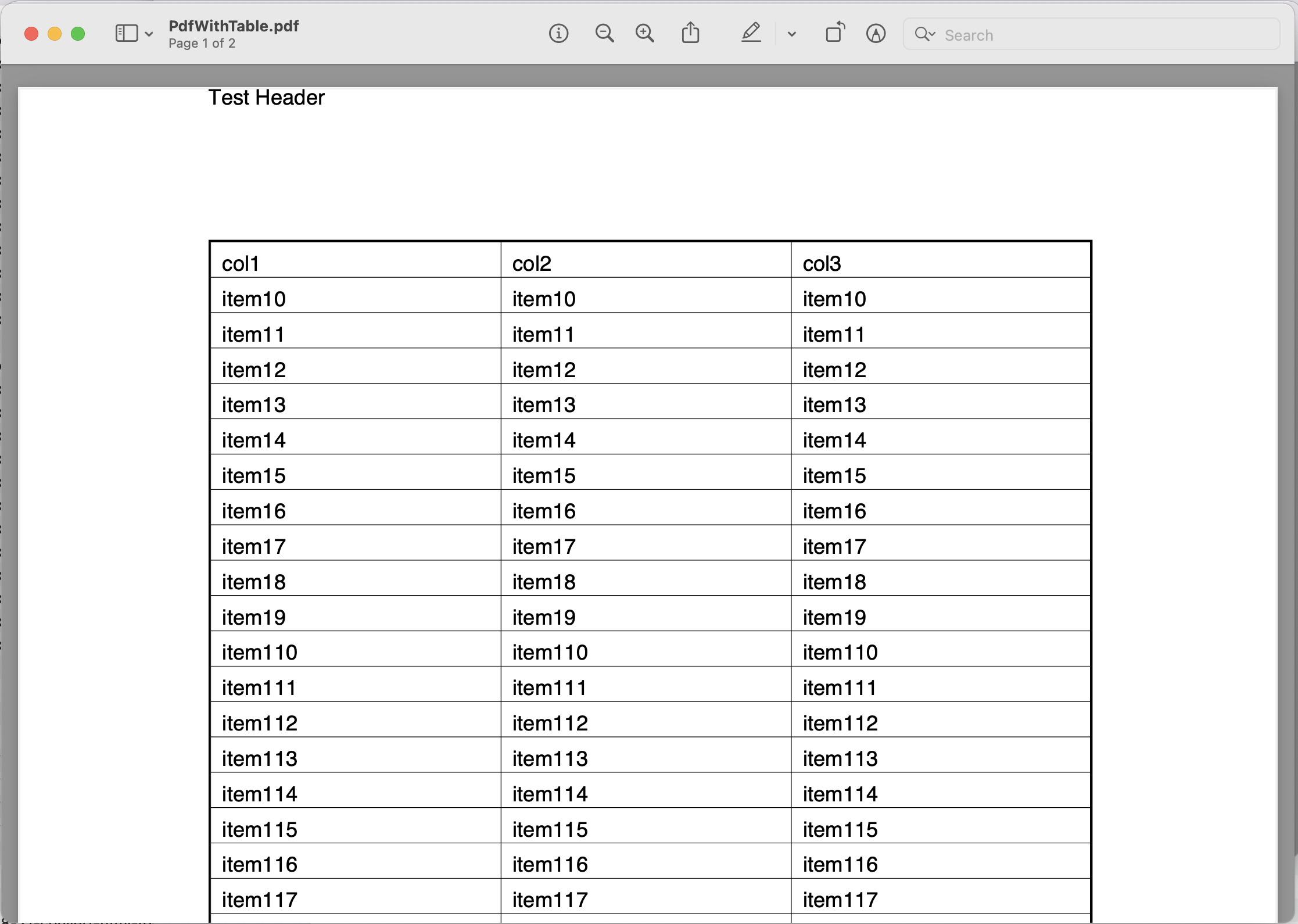
Εικόνα 1: - Εισαγωγή αρχείου για εξαγωγή PDF σε Κείμενο.
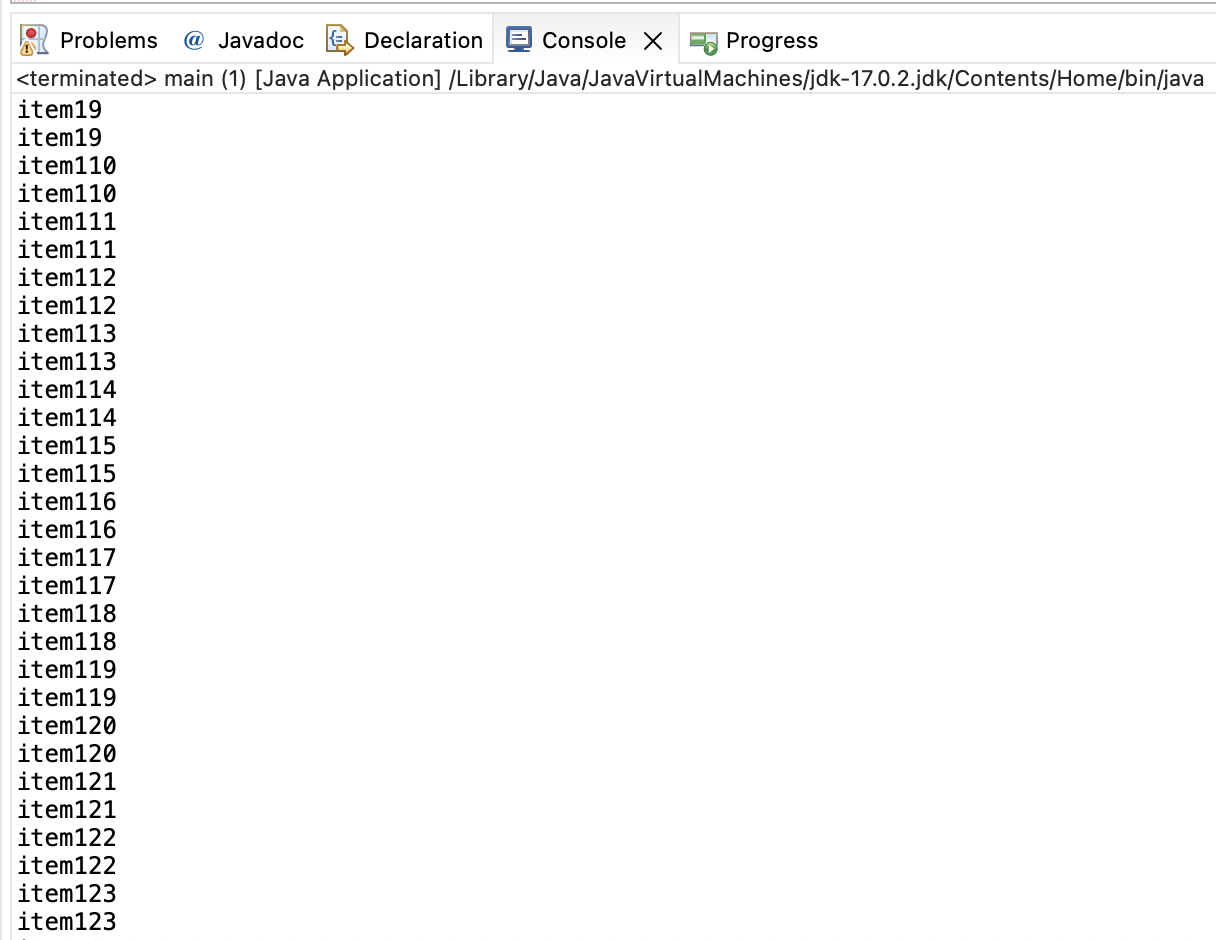
Εικόνα 2: - Εξαγωγή κειμένου από προεπισκόπηση PDF
// για περισσότερα παραδείγματα, επισκεφθείτε τη διεύθυνση https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-java/tree/master/Examples/src/main/java/com/aspose/asposecloudpdf/examples
try
{
// Λάβετε ClientID και ClientSecret από https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// δημιουργήστε μια παρουσία του PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// όνομα του εισαγόμενου εγγράφου PDF
String name = "PdfWithTable.pdf";
// διαβάστε το περιεχόμενο του αρχείου εισόδου PDF
File file = new File(name);
// μεταφορτώστε PDF στο χώρο αποθήκευσης cloud
pdfApi.uploadFile("input.pdf", file, null);
// Χ-συντεταγμένη κάτω - αριστερή γωνία
Double LLX = 500.0;
// Y - συντεταγμένη κάτω αριστερής γωνίας.
Double LLY = 500.0;
// X - συντεταγμένη πάνω δεξιά γωνία.
Double URX = 800.0;
// Y - συντεταγμένη πάνω δεξιά γωνία.
Double URY = 800.0;
// καλέστε το API για να μετατρέψετε PDF σε κείμενο
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
// Διέλευση μέσω μεμονωμένης εμφάνισης κειμένου
for(int counter=0; counter <=response.getTextOccurrences().getList().size()-1; counter++)
{
// γράψτε περιεχόμενο κειμένου στην κονσόλα
System.out.println(response.getTextOccurrences().getList().get(counter).getText());
}
System.out.println("Extract Text from PDF successful !");
}catch(Exception ex)
{
System.out.println(ex);
}
Τώρα ας προσπαθήσουμε να κατανοήσουμε το παραπάνω καθορισμένο απόσπασμα κώδικα:
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
Δημιουργήστε μια παρουσία του PdfApi ενώ μεταβιβάζετε τα εξατομικευμένα διαπιστευτήρια ως ορίσματα.
File file = new File(name);
pdfApi.uploadFile("input.pdf", file, null);
Διαβάστε το PDF εισόδου χρησιμοποιώντας το αντικείμενο File και μεταφορτώστε το στο χώρο αποθήκευσης cloud χρησιμοποιώντας τη μέθοδο uploadFile(…) της κλάσης PdfAPi. Σημειώστε ότι το αρχείο μεταφορτώνεται με το όνομα που χρησιμοποιείται στη μέθοδο uploadFile.
TextRectsResponse response = pdfApi.getText("input.pdf", LLX, LLY, URX, URY, null, null, null, null, null);
Τώρα καλέστε τη μέθοδο getText(..) όπου καθορίζουμε το όνομα του αρχείου εισόδου PDF, τις ορθογώνιες διαστάσεις στη σελίδα από την οποία πρέπει να εξαγάγουμε το περιεχόμενο κειμένου και, να επιστρέψουμε το εξαγόμενο περιεχόμενο στο αντικείμενο TextRectsResponse.
response.getTextOccurrences().getList().get(counter).getText()
Τέλος, για να εκτυπώσουμε το περιεχόμενο κειμένου που έχει εξαχθεί, θα επαναλάβουμε όλα τα TextOccurances και θα τα εμφανίσουμε στην κονσόλα.
PDF σε κείμενο χρησιμοποιώντας εντολές cURL
Εκτός από το απόσπασμα κώδικα Java, μπορούμε επίσης να εκτελέσουμε λειτουργία pdftotext χρησιμοποιώντας εντολές cURL. Τώρα, μία από τις προϋποθέσεις για αυτήν την προσέγγιση είναι να δημιουργήσετε ένα διακριτικό πρόσβασης JWT (με βάση τα διαπιστευτήρια πελάτη) χρησιμοποιώντας την ακόλουθη εντολή.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Μόλις δημιουργηθεί το JWT, εκτελέστε την ακόλουθη εντολή για να εξαγάγετε κείμενο από το αρχείο PDF που είναι ήδη διαθέσιμο στο cloud storage.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/input.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Γρήγορη συμβουλή
Ψάχνετε για εφαρμογή χωρίς κείμενο PDF σε κείμενο! Δοκιμάστε να χρησιμοποιήσετε τον [PDF Parser] (https://products.aspose.app/pdf/parser).
Τελικές παρατηρήσεις
Συμπερασματικά, η εξαγωγή κειμένου από αρχεία PDF χρησιμοποιώντας Java μπορεί να είναι μια ισχυρή λύση για όσους θέλουν να αυτοματοποιήσουν τις ανάγκες επεξεργασίας και ανάλυσης δεδομένων τους. Με τη βοήθεια αυτού του οδηγού, έχετε τώρα μια σταθερή βάση για να χτίσετε και μπορείτε εύκολα να εφαρμόσετε τη δική σας λύση βασισμένη σε Java για εξαγωγή κειμένου από έγγραφα PDF. Είτε θέλετε να εξαγάγετε κείμενο για ανάλυση δεδομένων, μηχανική εκμάθηση ή οποιονδήποτε άλλο σκοπό, η Java παρέχει μια ευέλικτη και αξιόπιστη πλατφόρμα για τις ανάγκες σας. Προχωρήστε λοιπόν και δοκιμάστε τις δεξιότητές σας που αποκτήσατε πρόσφατα!
Εάν ενδιαφέρεστε να εξερευνήσετε άλλες συναρπαστικές δυνατότητες που προσφέρονται από το API, εξερευνήστε την Τεκμηρίωση προϊόντος. Τέλος, εάν αντιμετωπίσετε οποιοδήποτε πρόβλημα κατά τη χρήση του API ή εάν έχετε οποιοδήποτε σχετικό ερώτημα, μη διστάσετε να επικοινωνήσετε μαζί μας μέσω του δωρεάν Φόρουμ Υποστήριξης Προϊόντων.
Σχετικά Άρθρα
Επισκεφτείτε τους παρακάτω συνδέσμους για να μάθετε περισσότερα σχετικά με: