
Sådan konverteres PDF til tekst i Python
Dagens digitale verden har en overflod af information, og evnen til at udtrække tekst fra PDF-dokumenter er blevet ikke bare en bekvemmelighed, men en nødvendighed. Forestil dig, at du gennemsøger en lang PDF-fil, søger efter den vigtige information, du skal citere i din forskning, eller måske administrerer du et lager af dokumenter, der søger at udtrække data til analyse. I disse scenarier og mange flere fremstår evnen til ubesværet at konvertere PDF-indhold til almindelig tekst som en game-changer. Denne artikel udforsker det dybe formål og de ubestridelige fordele ved at udtrække tekst fra PDF-filer ved hjælp af Python Cloud SDK. Denne transformation giver enkeltpersoner og organisationer mulighed for effektivt at administrere, analysere og bruge digitalt indhold i en verden, hvor information er af stor betydning.
- PDF til tekstkonvertering REST API
- Uddrag tekst fra PDF i Python
- PDF til tekstkonvertering ved hjælp af cURL-kommando
PDF til tekstkonvertering REST API
Opnåelse af tekstudtræk fra PDF-dokumenter gøres problemfrit og effektivt med Aspose.PDF Cloud SDK for Python. Denne alsidige SDK giver dig mulighed for ubesværet at konvertere PDF-indhold til almindelig tekst og låse op for informationen, der er gemt i disse digitale dokumenter.
Cloud SDK er tilgængelig til gratis download over PIP og GitHub repository. Udfør nu følgende kommando på terminal/kommandoprompten for at installere den seneste version af SDK:
pip install asposepdfcloud
Hvis du bruger PyCharm IDE, kan du tilføje SDK direkte som en afhængighed i dit projekt.
Fil ->Indstillinger ->Projekt ->Python-tolk ->asposepdfcloud
Efter installationen er det næste store trin et gratis abonnement på vores cloud-tjenester via Aspose.Cloud dashboard. Hvis du har en GitHub- eller Google-konto, skal du blot tilmelde dig eller klikke på knappen Opret en ny konto. Log nu ind på dashboardet og få dit personlige klient-id og klienthemmelighedsoplysninger.
Uddrag tekst fra PDF i Python
Følg venligst instruktionerne nedenfor for at udtrække tekst fra PDF-dokumenter ved hjælp af Python SDK.
- For det første skal du oprette en forekomst af ApiClient-klassen, mens du angiver Client ID Client Secret som argumenter.
- For det andet skal du oprette en forekomst af PdfApi-klassen, som tager ApiClient-objektet som et input-argument.
- Kald nu metoden gettext(…), mens du giver LLX, LLY, URX og URY koordinater.
def extractText():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# opret PdfApi-instans, mens du sender PdfApiClient som argument
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'awesomeTable.pdf'
# Kald metoden til at udtrække tekst
response = pdf_api.get_text(name = input_file, llx=0,lly=0, urx=800, ury =800)
print(response)
# udskriv besked i konsollen (valgfrit)
print('Text Extracted successfully from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
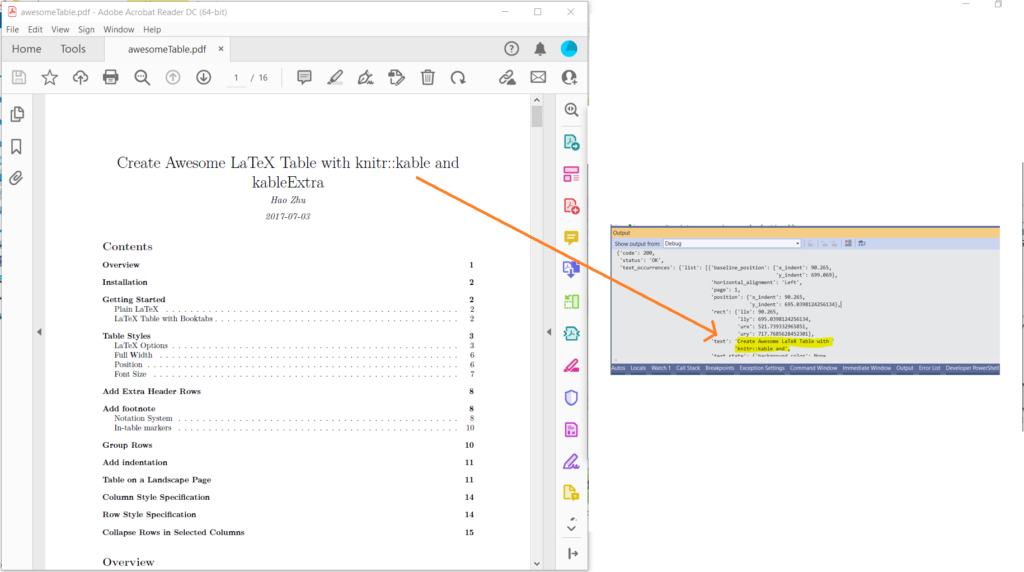
Billede 1:- PDF til tekst forhåndsvisning.
Hvis du har brug for at udtrække teksten fra en bestemt side i dokumentet, prøv venligst at bruge GetPageText API, som tager sidenummer som et argument.
PDF til tekstkonvertering ved hjælp af cURL-kommando
Oplev den sømløse transformation af PDF-indhold til almindelig tekst ved hjælp af den kraftfulde kombination af Aspose.PDF Cloud- og cURL-kommandoer. Denne dynamiske integration forenkler ikke kun PDF til tekstkonvertering, men tilbyder også adskillige fordele, der forbedrer din dokumenthåndtering og tekstudtrækningsoplevelse.
Bemærk venligst, at en forudsætning under denne tilgang er at generere et JSON Web Token (JWT) baseret på dine klientoplysninger. Dette trin er obligatorisk, da vores API’er kun er tilgængelige for registrerede brugere. Udfør venligst følgende kommando for at generere JWT-tokenet.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Når vi har JWT-tokenet, kan vi bruge følgende kommando til at konvertere PDF til tekst ved at udtrække alt tekstindhold. Outputtet gemmes som en almindelig tekstfil på det lokale drev.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/awesomeTable.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-o Extracted.txt
Eksemplet brugt i ovenstående eksempel kan downloades fra awesomeTable.pdf.
Konklusion
Udtrækning af tekst fra PDF-dokumenter er et kritisk krav i en verden fyldt med digital information. I vores udforskning af denne proces har vi undersøgt to dynamiske veje: en gennem den alsidige Aspose.PDF Cloud SDK til Python, og den anden via den kraftfulde kombination af Aspose.PDF Cloud og cURL-kommandoer.
Begge tilgange bygger bro mellem statisk PDF-indhold og dynamisk tekst, hvilket forbedrer den måde, vi administrerer, analyserer og bruger digital information på. Uanset om du vælger SDK’ets sofistikerede eller enkelheden ved cURL-kommandoer, fører begge veje til effektiv PDF til tekstkonvertering, hvilket giver dig mulighed for at låse op for det væld af tekstdata, der er gemt i PDF-dokumenter.
Relaterede artikler
Vi anbefaler også, at du besøger følgende links for at lære mere om: