
如何使用 Python 将 PDF 转换为文本
当今的数字世界信息丰富,从 PDF 文档中提取文本的能力不仅是一种便利,而且是一种必需品。想象一下,您正在筛选一个冗长的 PDF 文件,搜索研究中要引用的关键信息,或者您正在管理文档存储库,寻求提取数据进行分析。在这些场景以及更多场景中,轻松将 PDF 内容转换为纯文本的功能将成为改变游戏规则的关键。本文探讨了使用 Python Cloud SDK 从 PDF 中提取文本的深远目的和不可否认的好处。这种转变使个人和组织能够在信息至关重要的世界中有效地管理、分析和利用数字内容。
PDF 到文本转换 REST API
使用 Aspose.PDF Cloud SDK for Python 可以无缝高效地从 PDF 文档中提取文本。这款多功能 SDK 使您能够毫不费力地将 PDF 内容转换为纯文本,从而解锁存储在这些数字文档中的信息。
Cloud SDK 可通过 PIP 和 GitHub 存储库免费下载。现在在终端/命令提示符上执行以下命令来安装最新版本的 SDK:
pip install asposepdfcloud
如果您正在使用 PyCharm IDE,您可以直接将 SDK 作为依赖项添加到您的项目中。
文件 ->设置 ->项目 ->Python 解释器 ->asposepdfcloud
安装完成后,下一个重要步骤是通过 Aspose.Cloud 仪表板 免费订阅我们的云服务。如果您有 GitHub 或 Google 帐户,只需注册或单击 创建新帐户 按钮。现在登录仪表板并获取您的个性化客户端 ID 和客户端密钥详细信息。
使用 Python 从 PDF 中提取文本
请按照下面给出的说明使用 Python SDK 从 PDF 文档中提取文本。
- 首先,创建 ApiClient 类的实例,并提供客户端 ID 客户端密钥作为参数。
- 其次,创建一个 PdfApi 类的实例,该实例以 ApiClient 对象作为输入参数。
- 现在调用方法 gettext(…) 同时提供 LLX、LLY、URX 和 URY 坐标。
def extractText():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# 创建 PdfApi 实例并传递 PdfApiClient 作为参数
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'awesomeTable.pdf'
# 调用方法提取文本
response = pdf_api.get_text(name = input_file, llx=0,lly=0, urx=800, ury =800)
print(response)
# 在控制台中打印消息(可选)
print('Text Extracted successfully from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
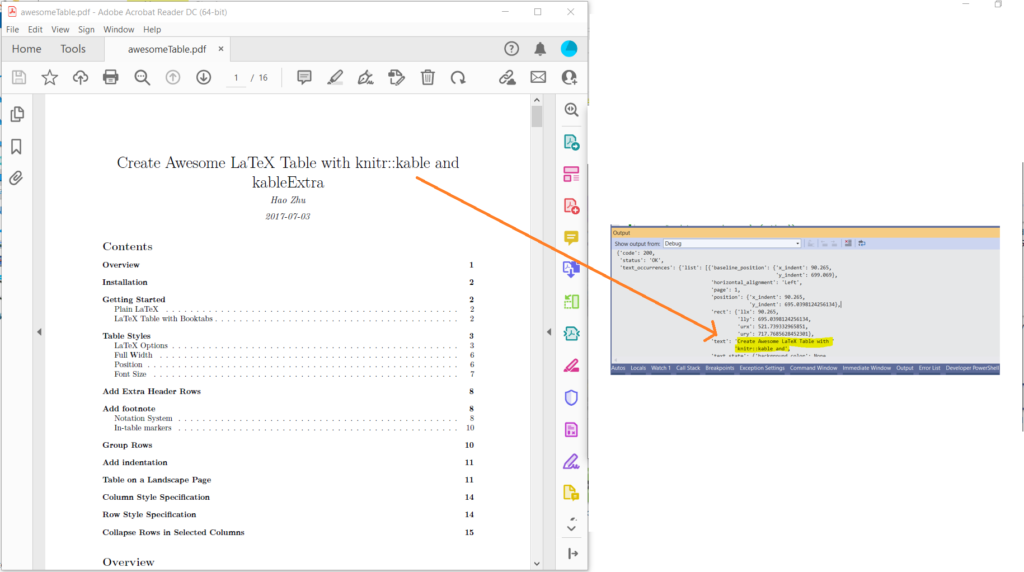
图 1:PDF 到文本预览。
如果您需要从文档的特定页面提取文本,请尝试使用以 pageNumber 作为参数的 GetPageText API。
使用 cURL 命令将 PDF 转换为文本
使用 Aspose.PDF Cloud 和 cURL 命令的强大组合,体验将 PDF 内容无缝转换为纯文本的过程。这种动态集成不仅简化了 PDF 到文本的转换,还提供了多种优势,可增强您的文档管理和文本提取体验。
请注意,此方法的先决条件是根据您的客户端凭据生成 JSON Web Token (JWT)。此步骤是强制性的,因为我们的 API 仅供注册用户访问。请执行以下命令来生成 JWT 令牌。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
一旦我们有了 JWT 令牌,我们就可以使用以下命令通过提取所有文本内容将 PDF 转换为文本。输出将保存为本地驱动器上的纯文本文件。
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/awesomeTable.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-o Extracted.txt
上述示例中使用的样本可以从awesomeTable.pdf下载。
结论
在充斥着数字信息的世界中,从 PDF 文档中提取文本是一项关键要求。在探索此过程的过程中,我们研究了两种动态途径:一种是通过多功能的 Aspose.PDF Cloud SDK for Python,另一种是通过 Aspose.PDF Cloud 和 cURL 命令的强大组合。
这两种方法都弥补了静态 PDF 内容和动态文本之间的差距,增强了我们管理、分析和利用数字信息的方式。无论您选择 SDK 的复杂性还是 cURL 命令的简单性,这两种途径都可以实现高效的 PDF 到文本转换,使您能够解锁 PDF 文档中隐藏的大量文本数据。
相关文章
我们还建议您访问以下链接以了解更多信息: