
Cómo convertir PDF a texto en Python
El mundo digital actual cuenta con una gran cantidad de información y la capacidad de extraer texto de documentos PDF se ha convertido no solo en una comodidad, sino en una necesidad. Imagínese que está revisando un archivo PDF extenso en busca de esa pieza de información fundamental para citar en su investigación, o tal vez esté administrando un repositorio de documentos y buscando extraer datos para su análisis. En estos escenarios y muchos más, la capacidad de convertir sin esfuerzo el contenido PDF en texto sin formato surge como un cambio radical. Este artículo explora el propósito profundo y los beneficios innegables de extraer texto de archivos PDF con Python Cloud SDK. Esta transformación permite a las personas y organizaciones administrar, analizar y utilizar de manera eficiente el contenido digital en un mundo donde la información es de gran importancia.
- API REST de conversión de PDF a texto
- Extraer texto de un PDF en Python
- Conversión de PDF a texto mediante el comando cURL
API REST de conversión de PDF a texto
La extracción de texto de documentos PDF es sencilla y eficiente con Aspose.PDF Cloud SDK para Python. Este SDK versátil le permite convertir fácilmente contenido PDF en texto sin formato, lo que permite acceder a la información almacenada en estos documentos digitales.
El SDK de Cloud está disponible para su descarga gratuita en los repositorios PIP y GitHub. Ahora ejecute el siguiente comando en la terminal o en el símbolo del sistema para instalar la última versión del SDK:
pip install asposepdfcloud
Si está utilizando PyCharm IDE, puede agregar directamente el SDK como una dependencia en su proyecto.
Archivo ->Configuración ->Proyecto ->Intérprete de Python ->asposepdfcloud
Después de la instalación, el siguiente paso importante es una suscripción gratuita a nuestros servicios en la nube a través del panel de control de Aspose.Cloud. Si tiene una cuenta de GitHub o Google, simplemente regístrese o haga clic en el botón Crear una nueva cuenta. Ahora inicie sesión en el panel de control y obtenga su ID de cliente personalizado y los detalles de su secreto de cliente.
Extraer texto de un PDF en Python
Siga las instrucciones que se detallan a continuación para extraer texto de documentos PDF utilizando Python SDK.
- En primer lugar, cree una instancia de la clase ApiClient y proporcione el ID de cliente y el secreto del cliente como argumentos.
- En segundo lugar, cree una instancia de la clase PdfApi que tome el objeto ApiClient como argumento de entrada.
- Ahora llame al método gettext(…) mientras proporciona las coordenadas LLX, LLY, URX y URY.
def extractText():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# Crea una instancia de PdfApi mientras pasas PdfApiClient como argumento
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'awesomeTable.pdf'
# Llamar al método para extraer texto
response = pdf_api.get_text(name = input_file, llx=0,lly=0, urx=800, ury =800)
print(response)
# Imprimir mensaje en la consola (opcional)
print('Text Extracted successfully from PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
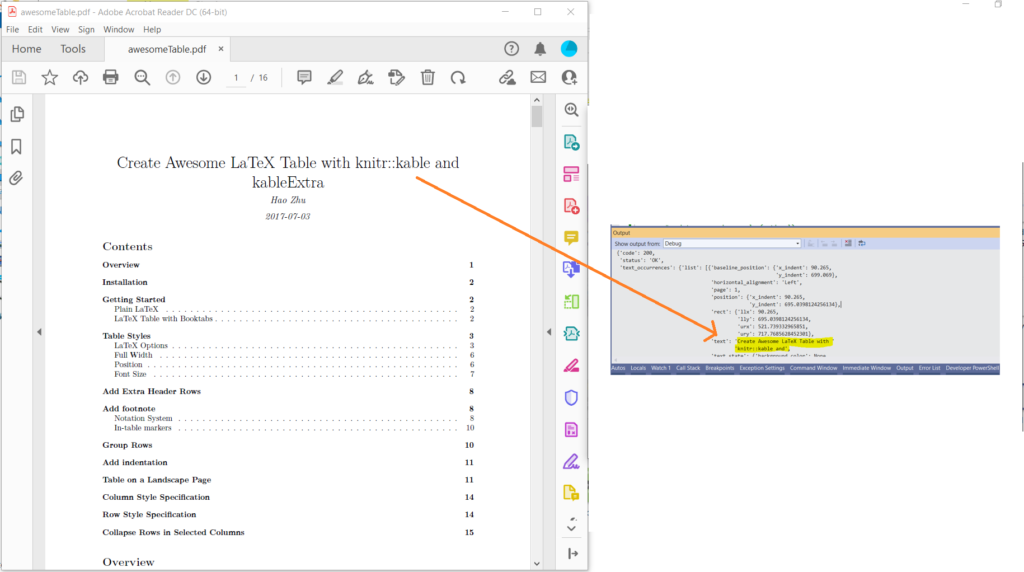
Imagen 1:- Vista previa de PDF a texto.
En caso de que necesite extraer el texto de una página específica del documento, intente utilizar la API GetPageText que toma pageNumber como argumento.
Conversión de PDF a texto mediante el comando cURL
Experimente la transformación perfecta de contenido PDF en texto sin formato mediante la poderosa combinación de Aspose.PDF Cloud y comandos cURL. Esta integración dinámica no solo simplifica la conversión de PDF a texto, sino que también ofrece varios beneficios que mejoran su experiencia de extracción de texto y administración de documentos.
Tenga en cuenta que un requisito previo de este enfoque es generar un token web JSON (JWT) basado en las credenciales de su cliente. Este paso es obligatorio, ya que nuestras API solo son accesibles para usuarios registrados. Ejecute el siguiente comando para generar el token JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Una vez que tenemos el token JWT, podemos usar el siguiente comando para convertir PDF a texto extrayendo todo el contenido textual. El resultado se guarda como un archivo de texto sin formato en la unidad local.
curl -v -X GET "https://api.aspose.cloud/v3.0/pdf/awesomeTable.pdf/text?splitRects=true&LLX=0&LLY=0&URX=800&URY=800" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-o Extracted.txt
La muestra utilizada en el ejemplo anterior se puede descargar desde awesomeTable.pdf.
Conclusión
La extracción de texto de documentos PDF es un requisito fundamental en un mundo inundado de información digital. En nuestra exploración de este proceso, hemos examinado dos vías dinámicas: una a través del versátil SDK Aspose.PDF Cloud para Python y la otra a través de la potente combinación de comandos Aspose.PDF Cloud y cURL.
Ambos enfoques cierran la brecha entre el contenido PDF estático y el texto dinámico, mejorando la forma en que administramos, analizamos y utilizamos la información digital. Ya sea que opte por la sofisticación del SDK o la simplicidad de los comandos cURL, ambas vías conducen a una conversión eficiente de PDF a texto, lo que le permite descubrir la gran cantidad de datos textuales ocultos en los documentos PDF.
Artículos relacionados
También recomendamos visitar los siguientes enlaces para conocer más sobre: