
Видобувайте PDF-зображення за допомогою .NET REST API.
У сучасну цифрову епоху, де інформації надлишок, а візуальні матеріали передають повідомлення ефективніше, ніж будь-коли, потреба видобувати зображення з PDF-файлів незаперечна. PDF — це популярний формат для обміну документами, і часто ці файли містять важливі зображення, до яких потрібно отримати доступ або змінити їх призначення. Незалежно від того, чи хочете ви використовувати зображення в презентаціях, включити їх у звіти чи поділитися ними на різних платформах, можливість видобувати зображення з PDF-файлів є потужним інструментом.
Ця стаття зосереджена на нагальній потребі у вилученні PDF-зображень і містить уявлення про ефективні способи досягнення цього за допомогою .NET Cloud SDK.
- .NET Cloud SDK для видобування зображень PDF
- Витягніть зображення PDF за допомогою C# .NET
- Видобувайте зображення з PDF за допомогою команд cURL
.NET Cloud SDK для видобування зображень PDF
Aspose.PDF Cloud SDK для .NET — це потужний набір інструментів, який не тільки дозволяє ефективно видобувати зображення, але й пропонує широкий спектр можливостей для керування та маніпулювання PDF документи. Крім того, він також пропонує функції, крім вилучення зображень, такі як вилучення тексту, водяні знаки, додавання анотацій і перетворення документів.
Тепер першим кроком є додавання посилання на SDK у наш проект. Для цього знайдіть Aspose.PDF-Cloud у менеджері пакетів NuGet у Visual Studio IDE та натисніть кнопку Додати пакет.
Вам також потрібно отримати облікові дані клієнта з хмарної інформаційної панелі. Якщо у вас немає облікового запису, просто створіть безкоштовний обліковий запис, дотримуючись інструкцій, наведених у швидкому запуску.
Витягніть зображення PDF за допомогою C# .NET
Давайте зосередимося на деталях вилучення зображень, щоб підняти обробку документів і вилучення даних на абсолютно новий рівень за допомогою C# .NET.
// Для отримання додаткових прикладів https://github.com/aspose-pdf-cloud/aspose-pdf-cloud-dotnet/tree/master/Examples
// Отримайте облікові дані клієнта з https://dashboard.aspose.cloud/
string clientSecret = "c71cfe618cc6c0944f8f96bdef9813ac";
string clientID = "163c02a1-fcaa-4f79-be54-33012487e783";
// створити екземпляр PdfApi
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
// Викличте API для видобування зображень PDF за допомогою API .NET REST
var response = pdfApi.PutImagesExtractAsJpeg("Instructions-for-Adding-Your-Logo-2.pdf", 1);
//
if (response != null && response.Status.Equals("OK"))
{
Console.WriteLine("Operation completed successfully !");
Console.ReadKey();
}
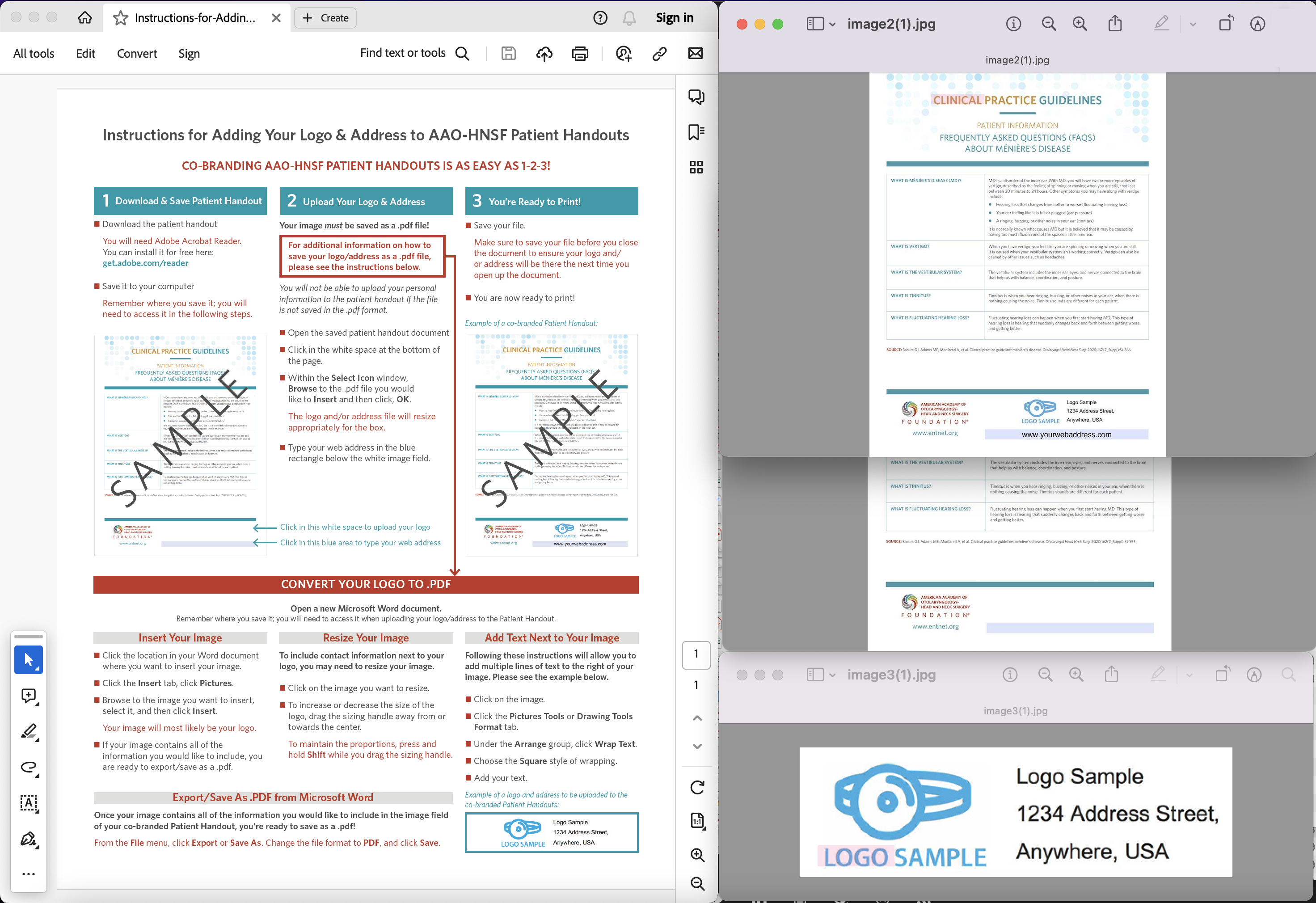
Попередній перегляд pf зображень, витягнутих із файлу PDF.
Нижче наведено короткі відомості про вказаний вище фрагмент коду.
PdfApi pdfApi = new PdfApi(clientSecret, clientID);
Створіть об’єкт класу PdfApi, передаючи облікові дані клієнта як вхідні аргументи.
var response = pdfApi.PutImagesExtractAsJpeg("Instructions-for-Adding-Your-Logo-2.pdf", 1);
Тепер викличте API, щоб отримати зображення з першої сторінки документа PDF. Після успішного завершення витягнуті зображення JPG зберігаються в хмарному сховищі.
Зразки PDF-файлів, використаних у наведеному вище прикладі, можна завантажити з [Instructions-for-Adding-Your-Logo-2.pdf](https://www.entnet.org/wp-content/uploads/2021/04/Instructions -for-Adding-Your-Logo-2.pdf).
Видобувайте зображення з PDF за допомогою команд cURL
Видобування зображень із PDF-файлів за допомогою команд Aspose.PDF Cloud і cURL є простим і ефективним процесом. Використовуючи команди cURL, ви можете надсилати HTTP-запити до Aspose.PDF Cloud API, щоб безперешкодно ініціювати вилучення зображень. Цей підхід спрощує процес, забезпечуючи ефективний підхід до видобування зображень із PDF без потреби у кодуванні.
Першим кроком у цьому підході є генерація маркера доступу JWT. Отже, виконайте таку команду:
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=163c02a1-fcaa-4f79-be54-33012487e783&client_secret=c71cfe618cc6c0944f8f96bdef9813ac" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Тепер виконайте наведену нижче команду, щоб отримати фотографії з 3-ї сторінки документа PDF і зберегти витягнуті зображення у форматі JPG у хмарному сховищі.
curl -v "https://api.aspose.cloud/v3.0/pdf/{inputPDF}/pages/3/images/extract/jpeg?width=0&height=0" \
-X PUT \
-H "accept: application/json" \
-H "authorization: Bearer {accessToken}" \
-d{}
Замініть inputPDF на назву вхідного PDF-файлу, доступного в хмарному сховищі, і замініть accessToken на маркер доступу JWT, згенерований вище.
Висновок
Підсумовуючи, можливість витягувати зображення з PDF-документів є життєво важливим компонентом для використання багатого візуального вмісту, який часто вбудовано в PDF-файли. У цій статті розглянуто два ефективні методи досягнення цього: використання Aspose.PDF Cloud SDK для .NET і використання Aspose.PDF Cloud за допомогою команд cURL. Таким чином, вибір між двома підходами залежить від конкретних вимог проекту, технічного досвіду та бажаних методів інтеграції, надаючи користувачам гнучкість для задоволення їхніх унікальних потреб.
корисні посилання
Схожі статті
Ми настійно рекомендуємо відвідати такі блоги: