
Aucun téléchargement ni installation d’Adobe Acrobat ou autre logiciel n’est requis et tout le traitement PDF est effectué dans le Cloud.
- Kit de développement logiciel (SDK) pour la manipulation de PDF dans le Cloud
- Rechercher et remplacer du texte à l’aide de Python
- Rechercher et remplacer du texte à l’aide de la commande cURL
Kit de développement logiciel (SDK) pour la manipulation de PDF dans le Cloud
Aspose.PDF Cloud est un SDK robuste offrant une large gamme de fonctionnalités pour gérer efficacement les fichiers PDF et rationaliser vos tâches de traitement de documents. L’une des fonctionnalités remarquables de ce SDK est la possibilité de rechercher et de remplacer du texte dans les documents PDF. Plongeons-nous dans le vif du sujet et exploitons tout le potentiel d’Aspose.PDF Cloud SDK pour Python pour révolutionner votre flux de travail d’édition PDF.
La première étape de l’utilisation de l’API consiste donc à installer le SDK Cloud, disponible gratuitement en téléchargement sur les référentiels PIP et GitHub. Exécutez simplement la commande suivante sur le terminal/l’invite de commande pour installer la dernière version du SDK sur le système.
pip install asposepdfcloud
MS Visual Studio
Lorsque vous utilisez Visual Studio, vous pouvez également ajouter la référence dans votre projet Python au sein du projet Visual Studio. Veuillez rechercher asposepdfcloud en tant que package dans la fenêtre d’environnement Python. Veuillez suivre les étapes numérotées dans l’image ci-dessous pour terminer le processus d’installation.
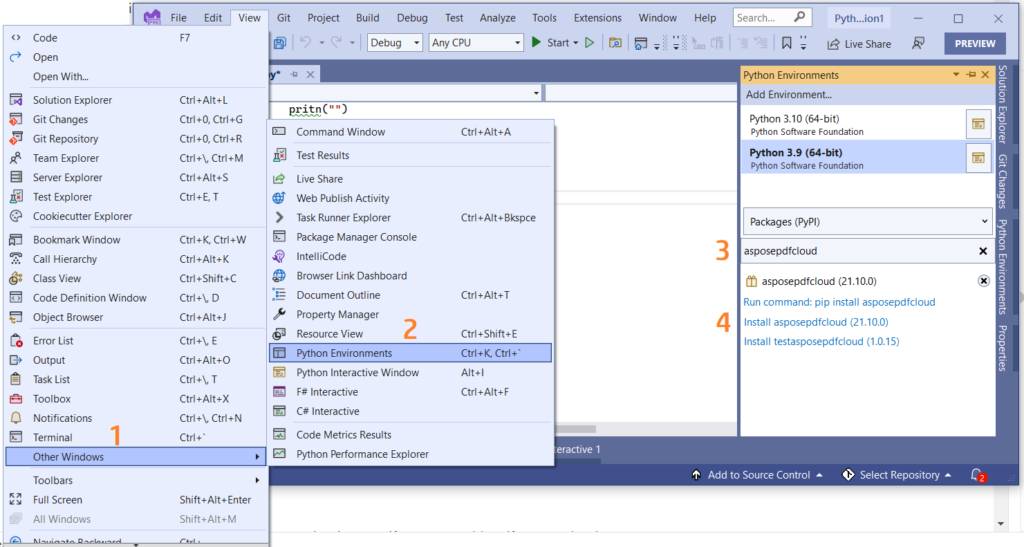
Image 1 : Package Aspose.PDF Cloud SDK pour Python.
Nous avons également besoin des informations d’identification du client pour accéder aux API Cloud, qui peuvent être obtenues à partir du tableau de bord Cloud. Inscrivez-vous simplement ou cliquez sur le bouton Créer un nouveau compte et fournissez les informations requises.
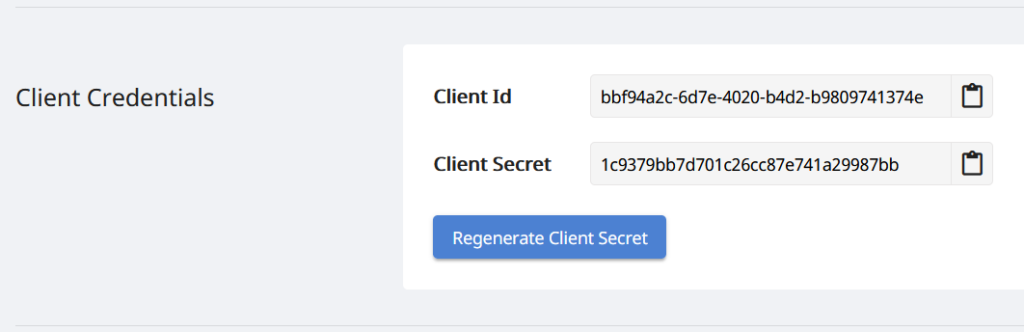
Image 2 : Informations d’identification du client sur le tableau de bord Aspose.Cloud.
Rechercher et remplacer du texte à l’aide de Python
Veuillez suivre les instructions ci-dessous pour rechercher une chaîne particulière et remplacer toutes ses occurrences dans le document PDF.
- Tout d’abord, créez une instance de la classe ApiClient tout en fournissant l’ID client et le secret client comme arguments.
- Deuxièmement, créez une instance de la classe PdfApi qui prend l’objet ApiClient comme argument d’entrée.
- Créer des variables spécifiant le document PDF d’entrée.
- Créez maintenant un objet de TextReplaceListRequest définissant les propriétés de remplacement de texte.
- Enfin, appelez la méthode postdocumenttextreplace(..) pour lancer l’opération de recherche et de remplacement et enregistrer le résultat dans le stockage Cloud.
def findAndReplaceText():
try:
#Client credentials
client_secret = "1c9379bb7d701c26cc87e741a29987bb"
client_id = "bbf94a2c-6d7e-4020-b4d2-b9809741374e"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# créer une instance PdfApi en passant PdfApiClient comme argument
pdf_api = PdfApi(pdf_api_client)
#source image file
input_file = 'URL2PDF.pdf'
# Propriétés du texte de remplacement
text_Replace_Request = asposepdfcloud.TextReplaceListRequest
{
"TextReplaces": [
{
"OldValue": "Productivity",
"NewValue": "Increased Productivity",
# "Regex": Vrai,
"TextState": {
"FontSize": 0,
"Font": "Arial",
"ForegroundColor": {
"A": 0,
"R": 252,
"G": 240,
"B": 3
},
"BackgroundColor": {
"A": 0,
"R": 252,
"G": 3,
"B": 248
},
"FontStyle": "Regular"
},
"Rect": {
"LLX": 0,
"LLY": 0,
"URX": 0,
"URY": 0
}
}
],
"DefaultFont": "Arial",
"StartIndex": 0,
"CountReplace": 0
}
# appeler l'API pour remplacer le texte dans le document PDF
response = pdf_api.post_document_text_replace(name = input_file, text_replace = text_Replace_Request)
print(response)
# imprimer un message dans la console (facultatif)
print('Text successfully Replaced in PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)

Image 3 : Aperçu de la sortie de remplacement de texte.
Dans l’extrait de code ci-dessus, veuillez observer spécifiquement deux paramètres, à savoir StartIndex et CountReplace. StartIndex définit l’occurrence spécifique du texte à partir de laquelle l’opération de remplacement de texte sera lancée et CountReplace définit les occurrences de texte qui doivent être remplacées. Dans l’image ci-dessous, remarquez que seules deux occurrences de la chaîne Product Family sont mises à jour à partir de l’index 2.

Image 4 : Deux occurrences de chaîne sont remplacées.
Pour votre information, l’entrée URL2PDF.pdf et le résultat Text-Replace-Output.pdf ont été joints.
Rechercher et remplacer du texte à l’aide de la commande cURL
En plus d’utiliser Aspose.PDF Cloud SDK pour Python, vous pouvez également exploiter la flexibilité des commandes cURL pour effectuer le remplacement de texte dans les documents PDF. cURL est un outil de ligne de commande qui vous permet d’effectuer des requêtes HTTP et d’interagir avec des services Web, ce qui en fait une option polyvalente pour l’intégration avec l’API Aspose.PDF Cloud. Avec les commandes cURL, vous pouvez facilement envoyer des requêtes aux points de terminaison de l’API et utiliser la fonction « Remplacer le texte » pour rechercher des modèles de texte spécifiques et les remplacer par un nouveau contenu.
Maintenant, veuillez exécuter la commande suivante pour générer le jeton JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bbf94a2c-6d7e-4020-b4d2-b9809741374e&client_secret=1c9379bb7d701c26cc87e741a29987bb" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Maintenant que nous avons généré notre jeton JWT personnalisé, nous devons exécuter la commande cURL suivante pour remplacer la chaîne de productivité dans le document PDF et enregistrer le document mis à jour dans le même stockage cloud.
curl -X POST "https://api.aspose.cloud/v3.0/pdf/URL2PDF.pdf/text/replace" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>" \
-H "Content-Type: application/json" \
-d "{ \"TextReplaces\": [ { \"OldValue\": \"Product Family\", \"NewValue\": \"Product Families\", \"Regex\": true, \"TextState\": { \"FontSize\": 0, \"Font\": \"Arial\", \"ForegroundColor\": { \"A\": 0, \"R\": 252, \"G\": 240, \"B\": 3 }, \"BackgroundColor\": { \"A\": 0, \"R\": 252, \"G\": 3, \"B\": 248 }, \"FontStyle\": \"Regular\" }, \"Rect\": { \"LLX\": 0, \"LLY\": 0, \"URX\": 0, \"URY\": 0 } } ], \"DefaultFont\": \"Arial\", \"StartIndex\": 2, \"CountReplace\": 2}"
Conclusion
En conclusion, la possibilité de rechercher et de remplacer du texte dans les documents PDF est une fonctionnalité précieuse qui peut grandement améliorer vos flux de travail de traitement de documents. Grâce à la puissance d’Aspose.PDF Cloud SDK pour Python et à la commodité des commandes cURL, vous disposez des outils nécessaires pour effectuer de manière transparente des tâches de remplacement de texte dans vos fichiers PDF. Que vous ayez besoin de mettre à jour des mots-clés spécifiques, de modifier des espaces réservés ou d’effectuer des modifications en masse sur plusieurs documents, ces solutions offrent flexibilité, efficacité et facilité d’intégration. En exploitant les capacités d’Aspose.PDF Cloud SDK pour Python ou en utilisant les commandes cURL, vous pouvez automatiser les opérations de remplacement de texte, améliorer la productivité et obtenir des résultats précis et cohérents. Commencez à exploiter ces puissants outils dès aujourd’hui et libérez le potentiel de votre traitement de documents PDF.
Liens utiles
Articles connexes
Nous vous recommandons également de visiter les liens suivants pour en savoir plus sur :