
Billeder er en af de integrerede komponenter til datadeling, og nogle applikationer gengiver direkte kildeindholdet i PDF-format. Men denne bekvemmelighed øger omkostningerne, når vi skal søge efter bestemt indhold inde i dokumentet. I det scenarie skal man gennemgå hele dokumentet manuelt for at finde den relevante information. Så den anbefalede tilgang er altid at generere filer, der er søgbare og nemme at administrere. Men hvis du har modtaget PDF-filerne, hvor du ikke kan kontrollere formatet af dokumenter ved kilden, så for dataarkivering og indeksering skal vi konvertere sådanne dokumenter til et søgbart format. I denne artikel vil vi diskutere detaljerne om, hvordan du udfører online PDF OCR og konverterer scannede / billed-PDF-filer til søgbare / tekst PDF-dokumenter.
PDF-behandling API
Aspose.PDF Cloud er vores prisvindende REST-arkitektur-baserede PDF-oprettelse og manipulation API. Ved at bruge den samme API kan du udføre en række operationer såsom Konverter EPUB til PDF, Konverter HTML til PDF, Konverter XPS til PDF, Konverter DOC og Doc X til PDF, Konverter XPS til PDF, indsæt billeder i nye eller eksisterende PDF-filer osv. Alle disse handlinger udføres i skyen, og API’en kan derfor tilgås fra enhver platform.
PDF OCR ved hjælp af cURL-kommandoen
cURL-kommandoerne er en nem måde at få adgang til Aspose.PDF Cloud via kommandolinjeterminalen. Men før du får adgang til API’erne, skal du først besøge Aspose.Cloud dashboard, og hvis du har GitHub eller Google-konto, skal du blot tilmelde dig. Ellers skal du klikke på knappen Opret en ny konto og angive de nødvendige oplysninger. Log nu ind på dashboardet ved hjælp af legitimationsoplysninger og udvid applikationssektionen fra dashboardet, og rul ned mod sektionen Klientlegitimationsoplysninger for at se Client ID og Client Secret detaljer.
Nu er næste trin at generere JSON Web Token (JWT), så API’erne er tilgængelige via kommandoprompten.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=a41d01ef-dfd5-4e02-ad29-bd85fe41e3e4&client_secret=d87269aade6a46cdc295b711e26809af" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Når vi har JWT-tokenet, skal du udføre følgende cURL-kommando i kommandolinjeterminalen.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/ocrscan.pdf/ocr?lang=eng" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Konverter scannet PDF til søgbar i Java
For at lette vores Java-programmører er der lavet en indpakning omkring Aspose.PDF Cloud, så alle funktionerne i Cloud API let kan tilgås i Java-kode. Tilsvarende skal vi bruge Aspose.PDF Cloud SDK for Java for at udføre OCR-handlingen på scannet PDF.
Så det første skridt er at installere SKD’en på systemet. Cloud SDK er tilgængelig til download over Maven og GitHub. Tilføj nu følgende detaljer i din pom.xml-fil for at downloade og bruge Aspose.Pdf.jar i dit Maven-byggeprojekt.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.1.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
For mere information, besøg venligst Sådan installeres Aspose.Cloud SDK’er.
Nedenstående trin definerer processen med COR-operation på billedets PDF-fil.
- Det første trin er at oprette et PdfApi objekt, mens du sender ClientID og Client hemmelige detaljer (tilgængelig på Aspose.Cloud dashboard).
- Opret en filinstans, og send billedfilens placering som et argument.
- Kald uploadFile(…)-metoden og send PDF-dokument og File-instans som argumenter.
- Det næste trin er at oprette en strenginstans og sætte dens værdi til den sprogkode, som kildefilen indeholder, dvs. “rus,eng”.
- Til sidst skal du kalde putSearchableDocument(…)-metoden for PdfApi og sende input-PDF-filnavn og videregive sprogkode som argumenter.
sprog til OCR-motor. understøttede værdier: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld, nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra eller deres kombination f.eks. eng,rus.
// Få ClientID og ClientSecret fra https://dashboard.aspose.cloud/
String clientId = "a41d01ef-dfd5-4e02-ad29-bd85fe41e3e4";
String clientSecret = "d87269aade6a46cdc295b711e26809af";
// oprette PdfApi instans
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// input PDF-dokument
String name = "ocrscan.pdf";
// Indlæs filen fra det lokale system
File file = new File("/Users/nayyershahbaz/Downloads/" + name);
// uploade filen til cloud storage
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// de sprog, der bruges i billedfilen
String lang = "rus,eng";
// udføre OCR på billede PDF-dokument
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
assertEquals(200, (int)response.getCode());
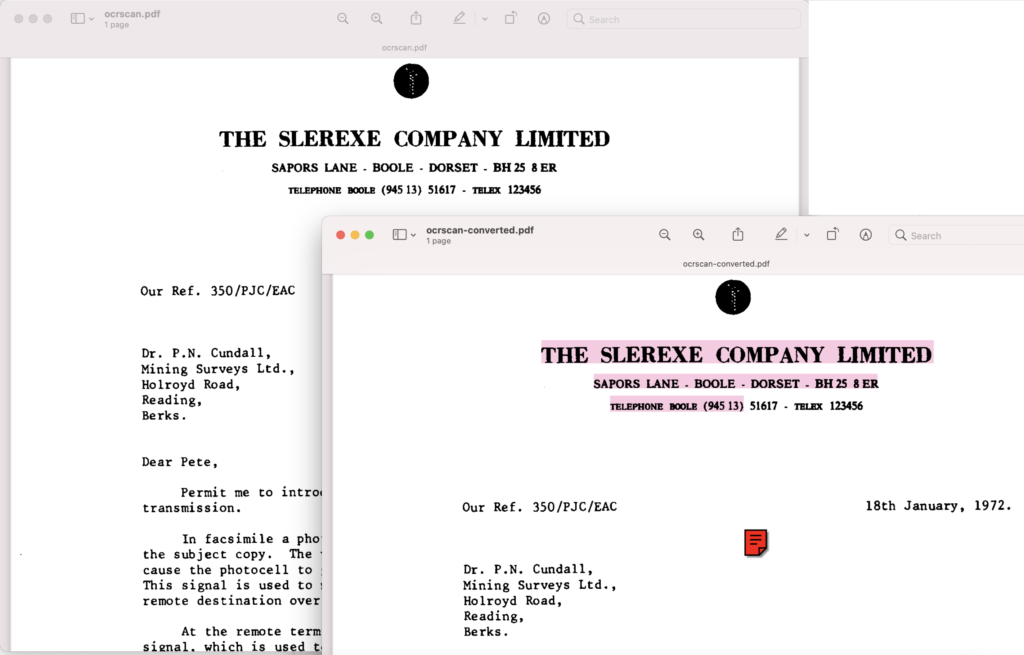
Billede 1:- OCR-udgangseksempel.
Eksempel på PDF-filer, der er brugt i ovenstående eksempel, kan downloades fra følgende links:
Konklusion
I denne artikel har vi lært nogle enkle trin til, hvordan du udfører online PDF OCR-operation og konverterer det scannede PDF-dokument til et søgbart PDF-dokument. Bortset fra OCR-operationer er SDK’et ret kraftfuldt og kan udføre en række andre operationer. For flere detaljer, besøg venligst Aspose.PDF Cloud Features.