
Images are one of the integral components for data sharing and some applications directly render the source content in PDF format. But this convenience increases the cost when we have to search certain content inside the document. In that scenario, one has to go through the whole document manually to find the relevant information. So the recommended approach is always to generate files that are searchable and easy to manage. However, if you have received the PDF files where you cannot control the format of documents at source, so for data archival and indexing, we need to convert such documents to a searchable format. In this article, we are going to discuss the details on how to perform online PDF OCR and convert scanned / image PDF files to searchable / text PDF documents.
PDF processing API
Aspose.PDF Cloud is our award-winning REST architecture-based PDF creation and manipulation API. Using the same API, you can perform a variety of operations such as Convert EPUB to PDF, Convert HTML to PDF, Convert XPS to PDF, Convert DOC and Doc X to PDF, Convert XPS to PDF, insert images in new or existing PDF files, etc. All these operations are performed in the cloud and therefore, the API can be accessed from any platform.
PDF OCR using the cURL command
The cURL commands are an easy way to access Aspose.PDF Cloud via the command line terminal. But before accessing the APIs, you need to first visit Aspose.Cloud dashboard and if you have GitHub or Google account, simply Sign Up. Otherwise, click on the Create a new Account button and provide the required information. Now login to the dashboard using credentials and expand the Applications section from the dashboard and scroll down towards the Client Credentials section to see Client ID and Client Secret details.
Now the next step is to generate JSON Web Token (JWT) so that the APIs are accessible through the command prompt.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=a41d01ef-dfd5-4e02-ad29-bd85fe41e3e4&client_secret=d87269aade6a46cdc295b711e26809af" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Once we have the JWT token, execute the following cURL command in command line terminal.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/ocrscan.pdf/ocr?lang=eng" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Convert scanned PDF to Searchable in Java
In order to facilitate our Java programmers, a wrapper around Aspose.PDF Cloud has been created so that all the features of Cloud API can easily be accessed in Java code. Similarly, in order to perform the OCR operation on scanned PDF, we need to use Aspose.PDF Cloud SDK for Java.
So the first step is to install the SKD on system. The Cloud SDK is available for download over Maven and GitHub. Now add the following details in your pom.xml file to download and use Aspose.Pdf.jar in your Maven build project.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.1.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
For more information, please visit How to install Aspose.Cloud SDKs.
Given below steps define the process of COR operation on image PDF file.
- The first step is to create a PdfApi object while passing ClientID and Client secret details (available at Aspose.Cloud dashboard).
- Create a File instance and pass the location of the image file as an argument.
- Call the uploadFile(…) method and pass PDF document and File instance as arguments.
- The next step is to create a string instance and set its value to the language code which the source file contains i.e. “rus,eng”.
- Finally, call the putSearchableDocument(…) method of PdfApi and pass input PDF file name and pass language code as arguments.
languages for OCR engine. supported values: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld, nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chi_sim, chi_tra or their combination e.g. eng,rus.
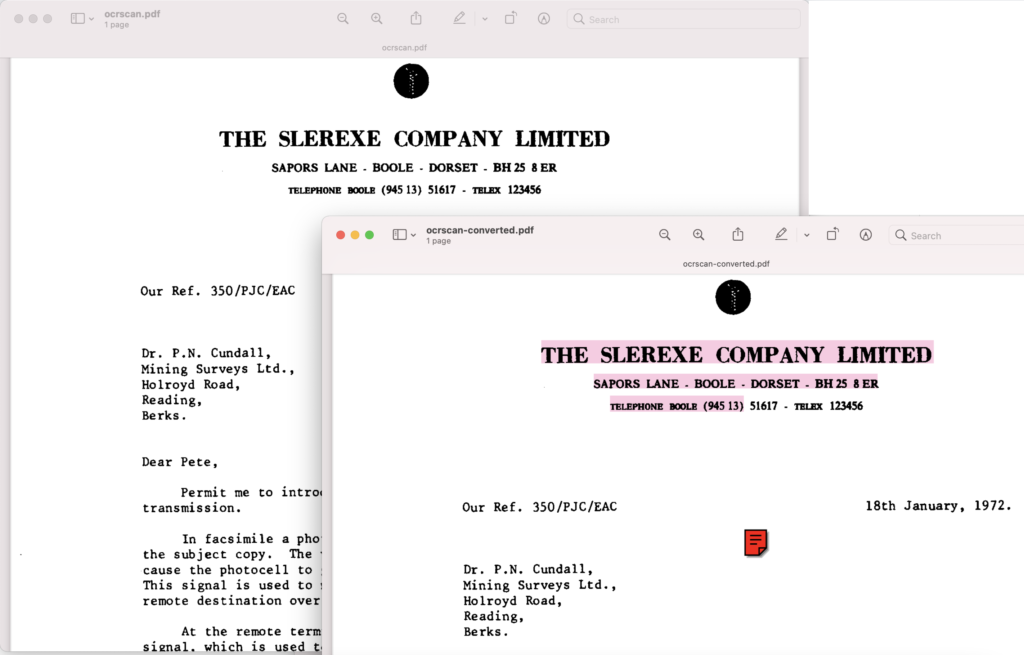
Image 1:- OCR output preview.
The sample PDF files used in the above example can be downloaded from the following links:
Conclusion
In this article, we have learned some simple steps on how to perform online PDF OCR operation and convert the scanned PDF document to a searchable PDF document. Other than OCR operations, the SDK is quite powerful and can perform a variety of other operations. For more details, please visit Aspose.PDF Cloud Features.