使用 Python SDK 从 Word 文档中提取页面的快速简便的方法。

拆分 Word 文档 | 从 Word 文档中提取页面作为单独的文件
在文档管理领域,经常需要从 Word 文档中划分、分离或提取特定部分。无论您处理的是大量研究论文、综合报告还是冗长的手稿,将它们分解成更易于管理的部分的任务既耗时又具有挑战性。在本文中,我们将探讨使用 Python Cloud SDK 实现此要求的步骤,使您能够简化文档管理任务并更高效地工作。
文字处理API
Aspose.Words Cloud 是我们专门针对 MS Word (DOCX, DOC, DOT, RTF, DOCM) 或 OpenDocument (ODT, OTT) 处理的解决方案。处理 Word 文档不需要第三方软件或 MS Office 自动化。只需调用 REST API 即可满足您的要求。由于 API 是基于 REST 的,因此您可以在任何平台上访问它们,包括桌面、Web、移动应用程序等。现在,根据本文的范围,我们将讨论如何将 Word 文件中的页面拆分为单独的 Word 文档的细节。API 还提供了自定义拆分操作的灵活性,即按页数、按页面范围拆分每一页(奇数页和偶数页)。
为了进一步方便我们的客户,我们创建了 Aspose.Words Cloud SDK for Python,它是 Cloud API 的包装器,因此您可以使用自己喜欢的编程语言享受 Word 文档处理的所有好处。因此,在继续操作之前,第一步是在本地系统上安装 SDK。它可在 PIP 和 GitHub 下载。在命令行终端上执行以下命令来安装 SDK:
pip install aspose-words-cloud
如果您使用Visual Studio作为IDE,您可以直接在项目中添加SDK的引用。
点击View ->Other Windows ->Python Environments选项。如下图。
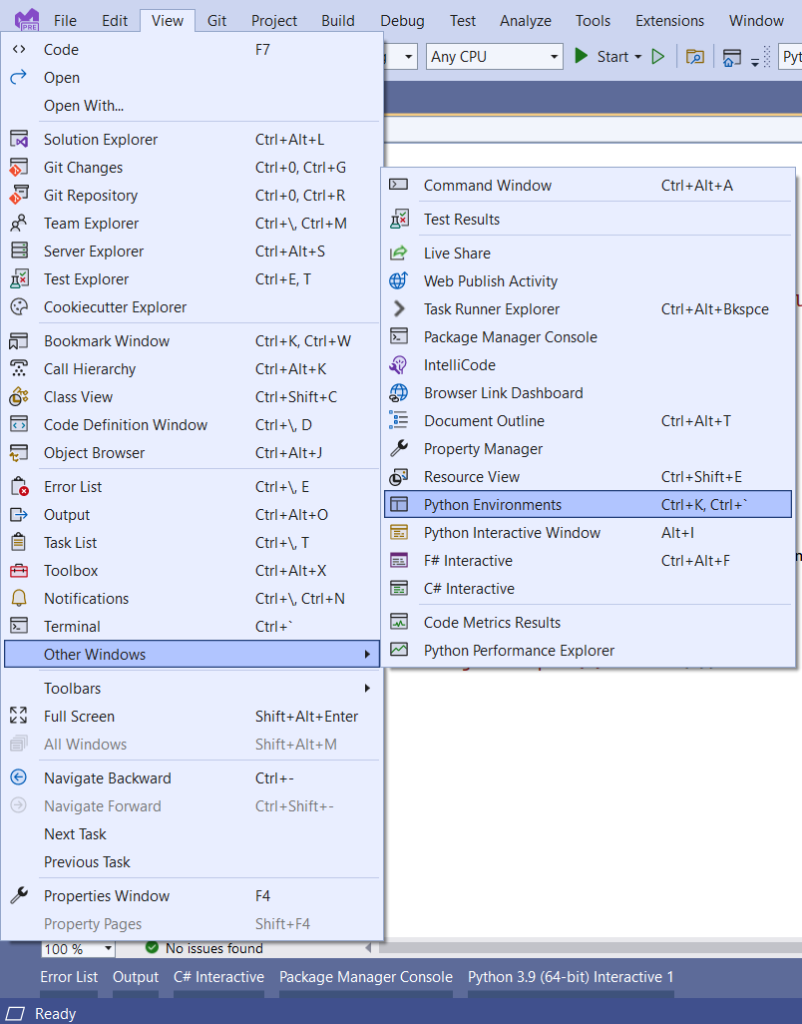
图 1:- Python 环境菜单选项。
在 Python 环境窗口的 Packages 字段下输入 aspose-word-cloud。然后单击 Install aspose-word-cloud (21.11.0) 链接。版本号可能会根据最新/当前发布版本而变化。参见下图。
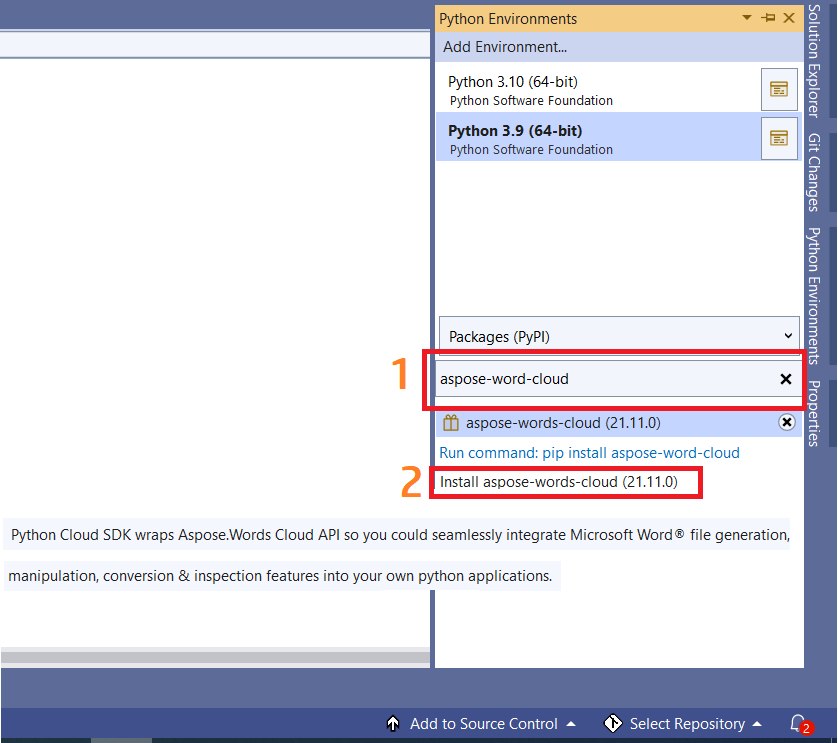
图 2:- aspose-words-cloud python 包。
使用 Python 在 Word 文档中拆分页面
请按照以下说明拆分云存储中已有的 Word 文档中的所有页面。
- 首先,我们需要初始化 WordsApi 的对象并传递客户端 ID 和客户端密钥作为参数。
- 其次,指定输入的 Word 文件的名称、结果输出格式、结果文件的名称以及对输出进行 zip 存档的参数。
- 使用 UploadFileRequest 对象将输入的 Word 文档上传到云存储。
- 现在创建 SplitDocumentRequest 的实例,同时传递第二步中定义的详细信息。
- 最后调用WordsApi类的splitdocument(…)方法对word文档进行拆分,拆分后的文件保存在映射的云存储中。
try:
# 创建 WordsApi 实例
words_api = WordsApi("88d1cda8-b12c-4a80-b1ad-c85ac483c5c5","406b404b2df649611e508bbcfcd2a77f")
# 输入word文档名称
inputFileName = 'source.doc'
# 生成的文件格式
resultantFormat = 'DOCX'
# 操作后生成的文档的名称。如果省略此参数
# 然后结果文件将以输入文档的名称保存
resultantFile = 'Split-File'
# 指示是否对输出进行 ZIP 处理的标志。
zipOutput = 'false'
# 将源 Word 文档上传到云存储
words_api.upload_file(asposewordscloud.models.requests.UploadFileRequest(open('C:\\Users\\Downloads\\'+inputFileName, 'rb'), "", None))
# 创建对象来分割文档
request = asposewordscloud.models.requests.SplitDocumentRequest(inputFileName, resultantFormat, None, None, None,
None, resultantFile,None, None, zipOutput, None)
# 启动 Word Split 操作
result = words_api.split_document(request)
# 在控制台中打印消息(可选)
print('Document Split process completed successfully !')
except ApiException as e:
print("Exception while calling WordsApi: {0}".format(e))

图 3:文档拆分操作的预览。
根据选定页面拆分文档
在本节中,我们将讨论如何根据所选页面拆分文档并将输出保存为 ZIP 存档的详细信息。代码片段与上面共享的几乎相同,只是我们需要指定要存档的输出的 Page From、Page To 和 True 值。
try:
# 创建 WordsApi 实例
words_api = WordsApi("88d1cda8-b12c-4a80-b1ad-c85ac483c5c5","406b404b2df649611e508bbcfcd2a77f")
# 输入word文档名称
inputFileName = 'source.doc'
# 生成的文件格式
resultantFormat = 'DOCX'
# 操作后生成的文档的名称。如果省略此参数
# 然后结果文件将以输入文档的名称保存
resultantFile = 'SplitOutput'
# 指示输出的标志应在 ZIP 存档中。
zipOutput = 'false'
# 将源 Word 文档上传到云存储
words_api.upload_file(asposewordscloud.models.requests.UploadFileRequest(open('C:\\Users\\Downloads\\'+inputFileName, 'rb'), "", None))
# 创建对象来分割文档
request = asposewordscloud.models.requests.SplitDocumentRequest(inputFileName, resultantFormat, None, None, None,
None, resultantFile,pageFrom, pageTo, zipOutput, None)
# 启动 Word Split 操作
result = words_api.split_document(request)
# 在控制台中打印消息(可选)
print('Document Split process completed successfully !')
except ApiException as e:
print("Exception while calling WordsApi: {0}".format(e))
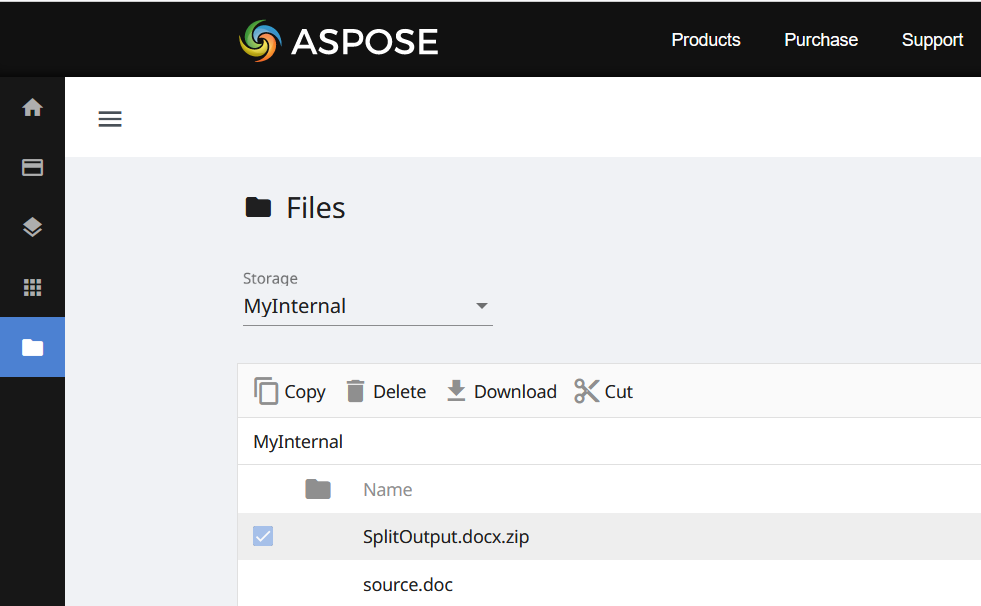
图 4:- 选定页面的文档拆分操作预览。
使用 cURL 命令从 Word 文档中提取页面
与其他 REST API 一样,Aspose.Words Cloud 也可以通过命令行终端中的 cURL 命令访问。但在继续操作之前,我们需要先根据客户端凭据生成 JWT 访问令牌。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
生成令牌后,请执行以下命令从 Word 文档中提取页面并将输出保存在云存储中。
curl -v -X PUT "https://api.aspose.cloud/v4.0/words/source.doc/split?format=DOCX&destFileName=Split-File&from=2&to=4&zipOutput=false" \
-H "accept: application/json" \
-H "Authorization: Bearer <JWT Token>"
结论
在本文中,我们探讨了使用 Python SDK 创建文档分割器的可能性,该分割器可以将 Word 文档分割为单独的页面文件。此外,根据您的要求,您可以使用 Python SDK 或使用 cURL 命令从 Word 文档中提取页面。请注意,我们相信集体成长和合作。因此,我们的 SDK 是根据 MIT 许可证开发的,其完整源代码可通过 Github 下载。如果需要,您可以根据您的要求下载和修改代码。如果您遇到任何问题或有任何其他疑问,请随时通过 免费产品支持论坛 与我们联系。
相关文章
我们建议您访问以下链接以了解更多信息: